Modèles statistiques
Cours 2
Les bases
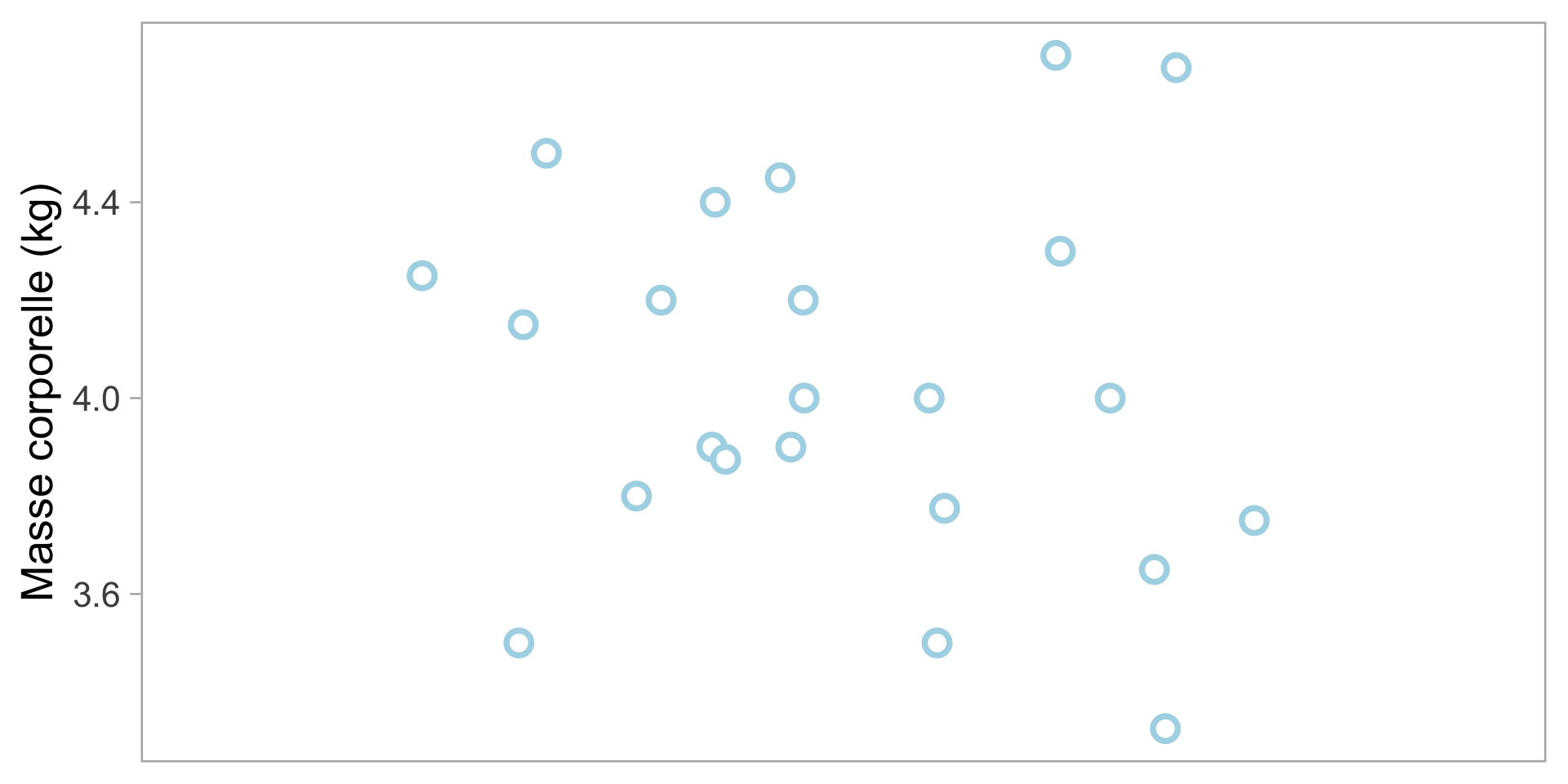
Décrire ces données
Peut être résumé avec la moyenne: \[ \overline{w}=\frac{\sum_{i = 1}^{n}{\textcolor{lightblue}{w_{i}}}}{n} \]
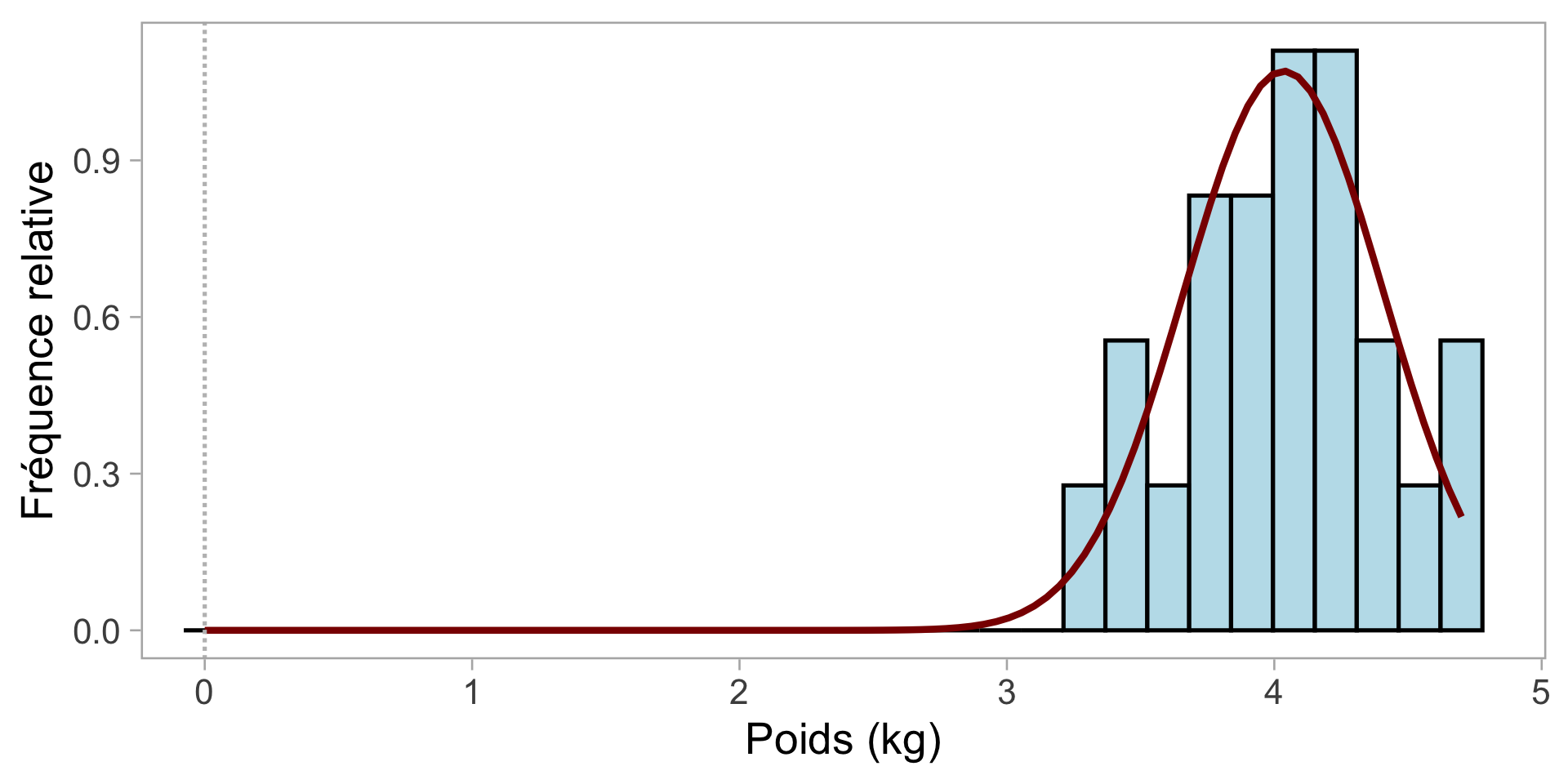
- \(\overline{w}=\) 4.03 kg
- Mais qu’en est-il de la variabilité?
Les bases
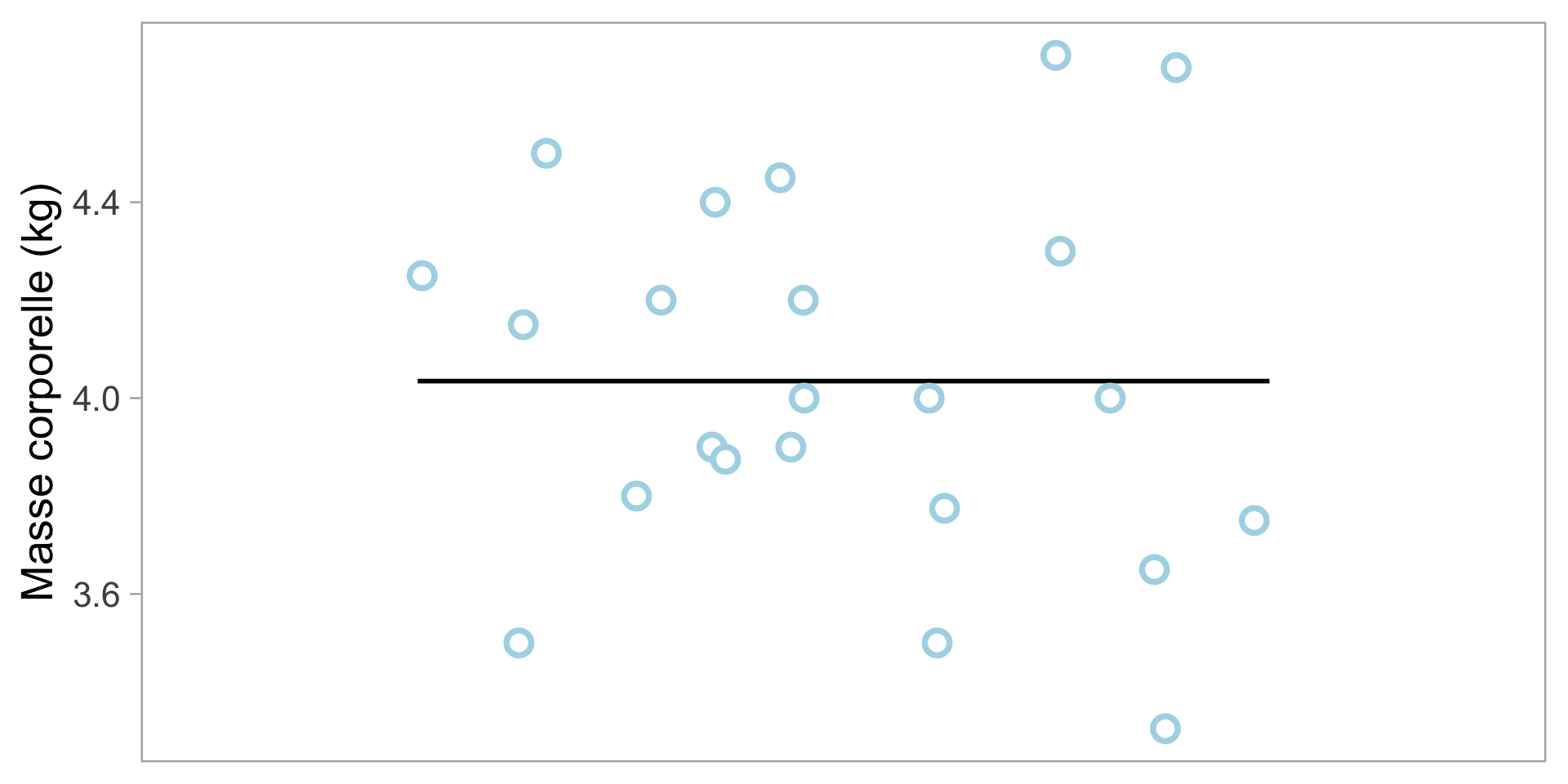
Décrire ces données
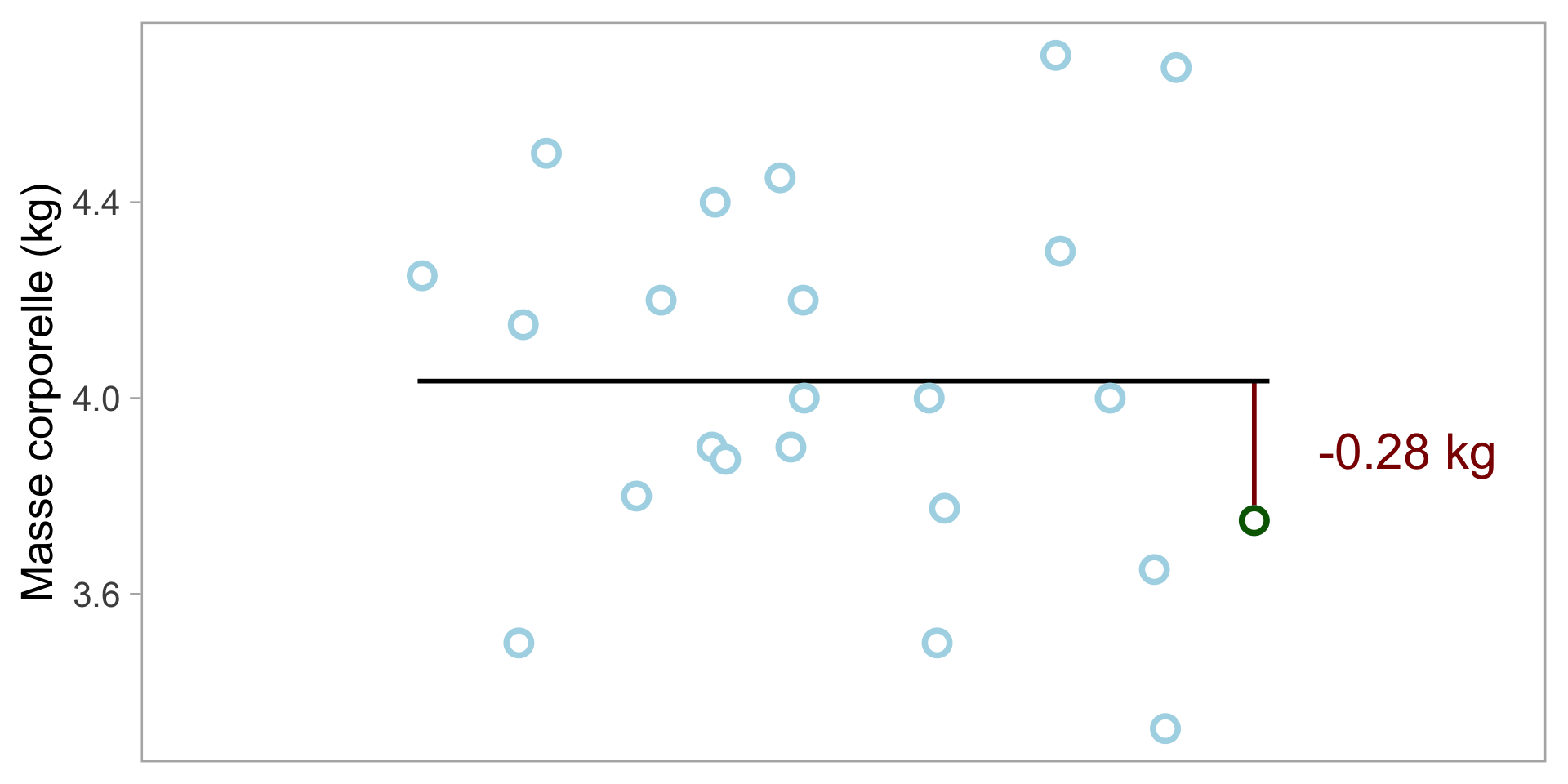
Mesure de la variabilité individuelle: Déviation
\[ \textcolor{darkgreen}{w_{i}} - \overline{w} \]
Les bases
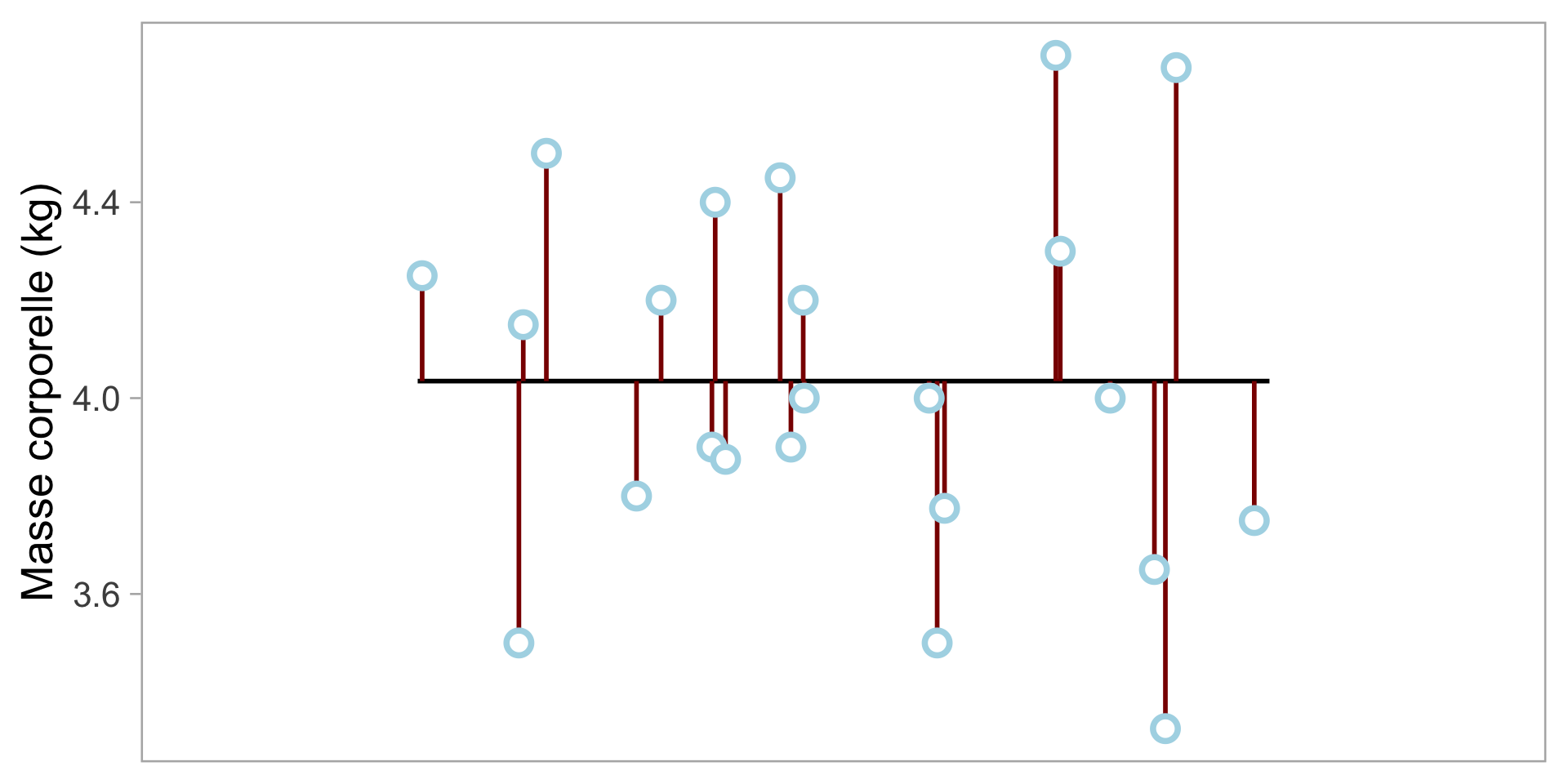
Décrire ces données
Mesure de la variabilité population : Écart-type
\[ \sigma=\sqrt{\frac{\sum_{i = 1}^{n}{(\textcolor{lightblue}{w_{i}} - \overline{w})^2}}{n}} \]
\(\sigma\) = 0.37 kg
Les bases
Mais, alors quoi? Quel est l’avantage de connaître cela?
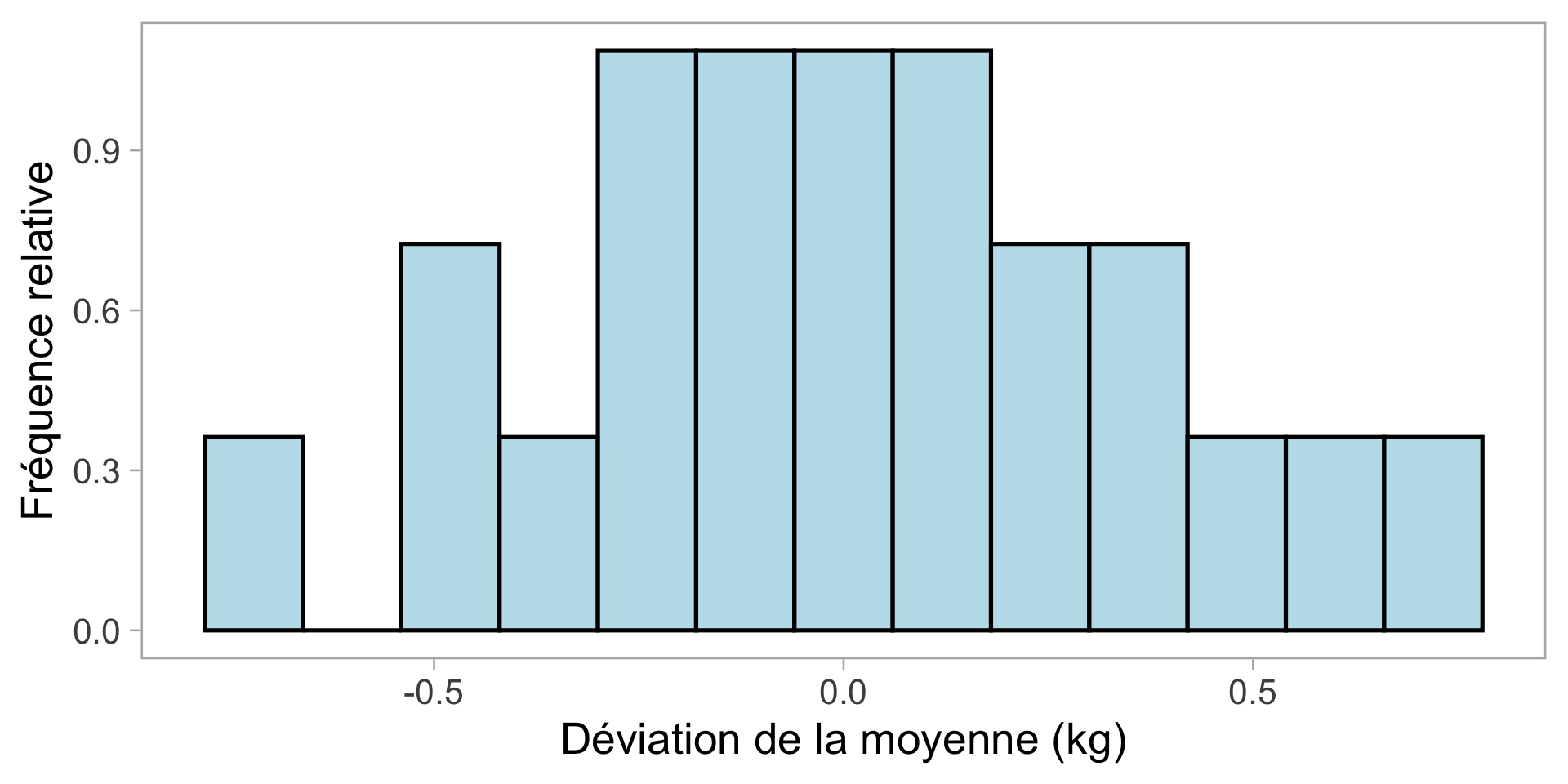
Le bruit n’est pas complètement aléatoire : la plupart des valeurs sont proches de la moyenne, peu s’écartent davantage.
Les bases
Mais, alors quoi? Quel est l’avantage de connaître cela?
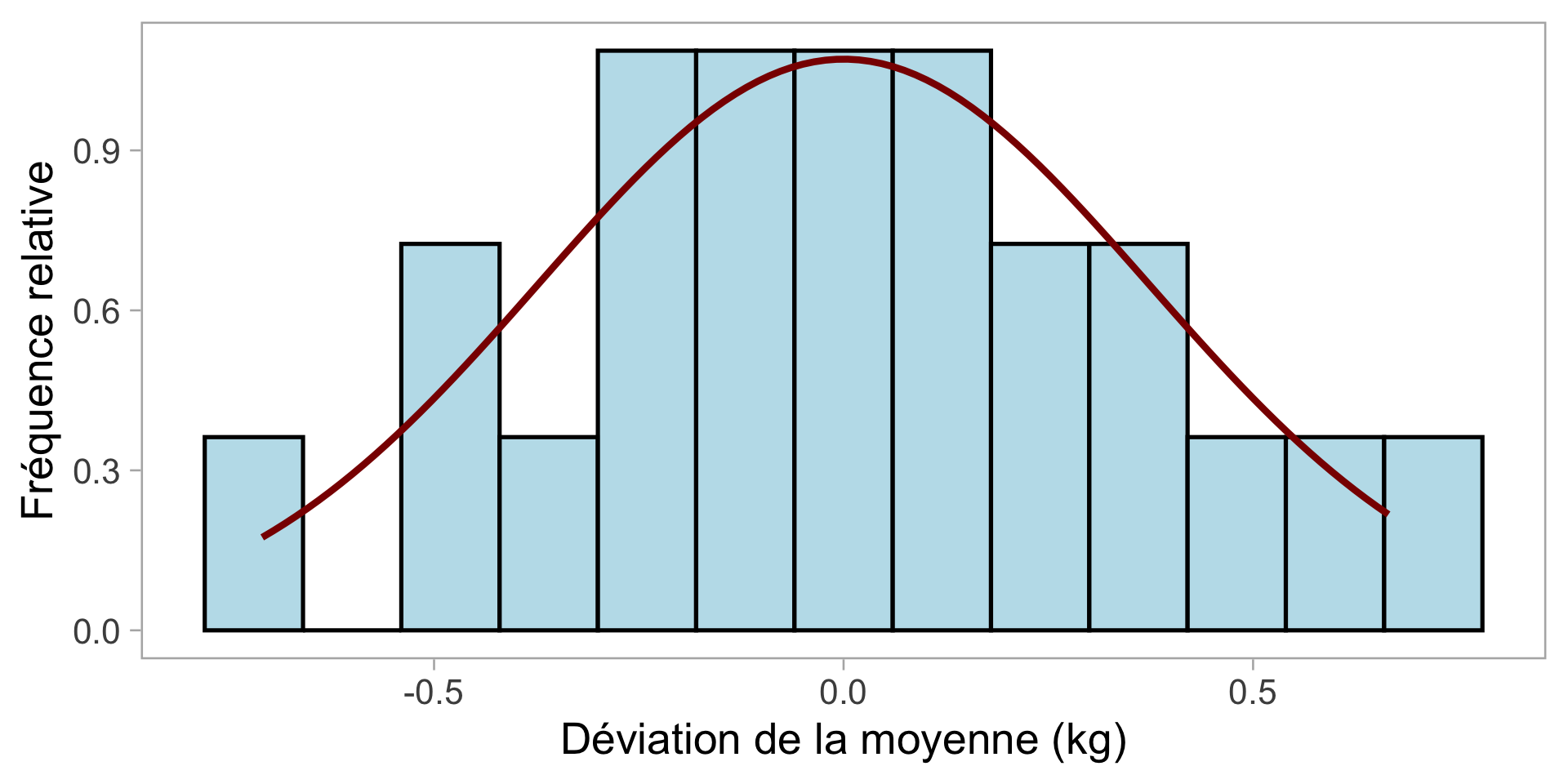
Le bruit n’est pas complètement aléatoire : la plupart des valeurs sont proches de la moyenne, peu s’écartent davantage.
De nombreux processus biologiques suivent une distribution normale
La distribution normale
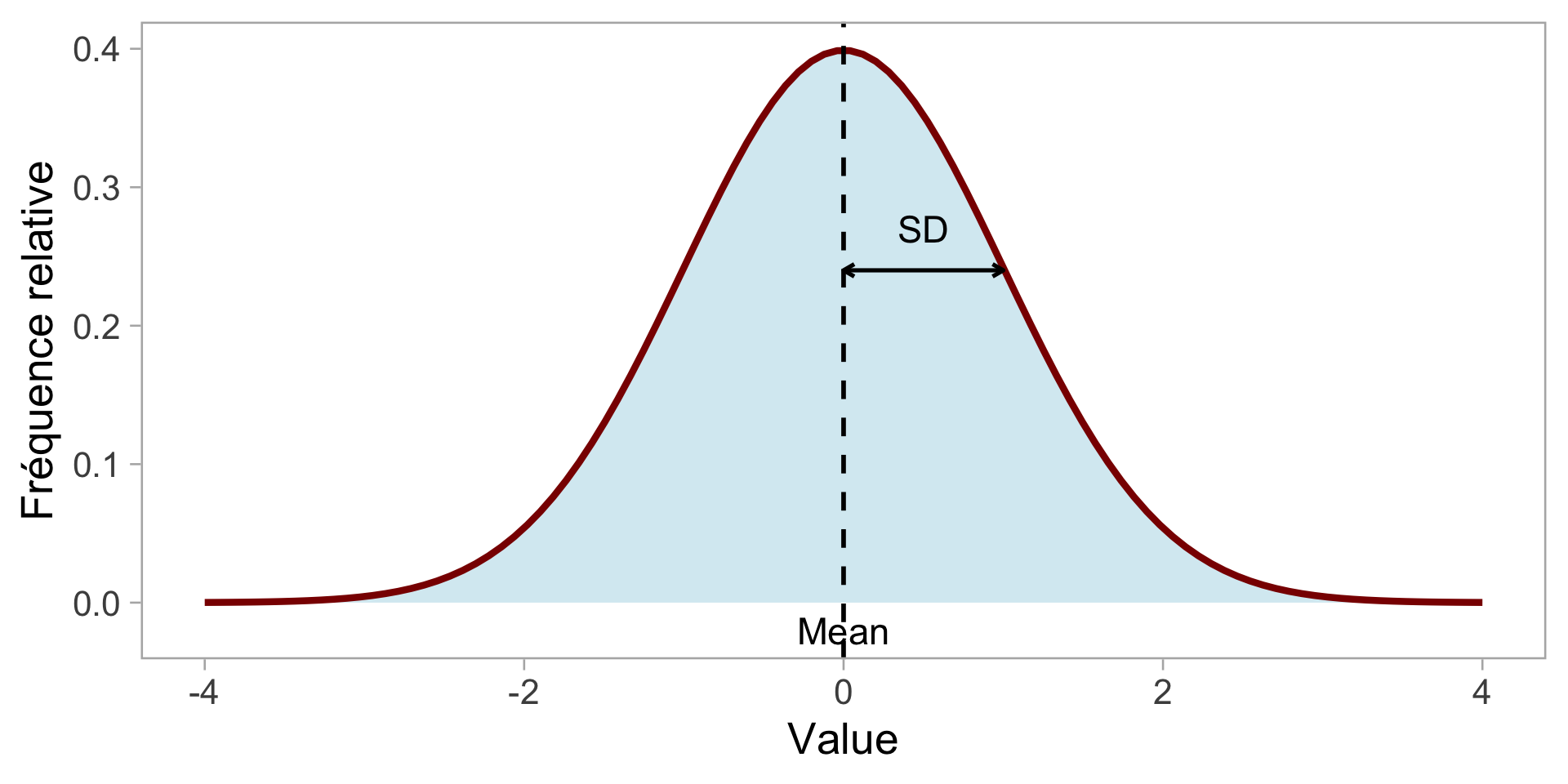
Peut être décrit avec
Moyenne \(\mu\) et
Écart type \(\sigma\)
La distribution normale
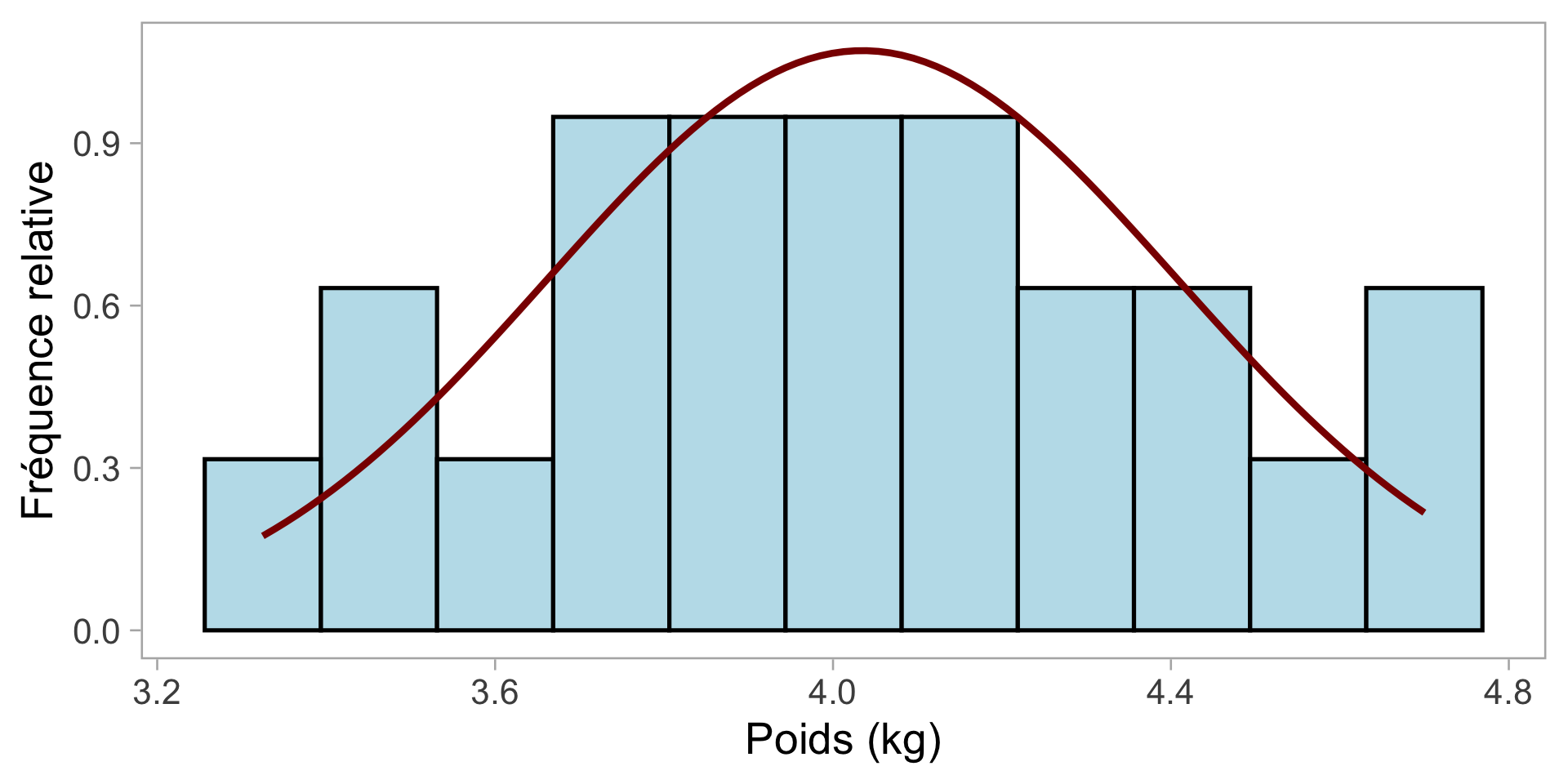
Connaître la distribution nous permet d’en savoir plus sur les données (c.-à-d. différent de 0 ou non ?)
Nous pouvons également simuler de nouvelles données
Il s’agit d’un modèle statistique !
Poids des manchots
Est-il vraiment intéressant de savoir si le poids diffère de 0? Qu’est-ce qui serait plus intéressant?
Non ! Mais
Relation entre la longueur et le poids
Différence de poids entre les espèces
Différence de relation entre longueur et poids
sont biologiquement plus intéressants !
Poids et Longueur
Nous avons déjà vu qu’il existe une relation entre le poids et la longueur.
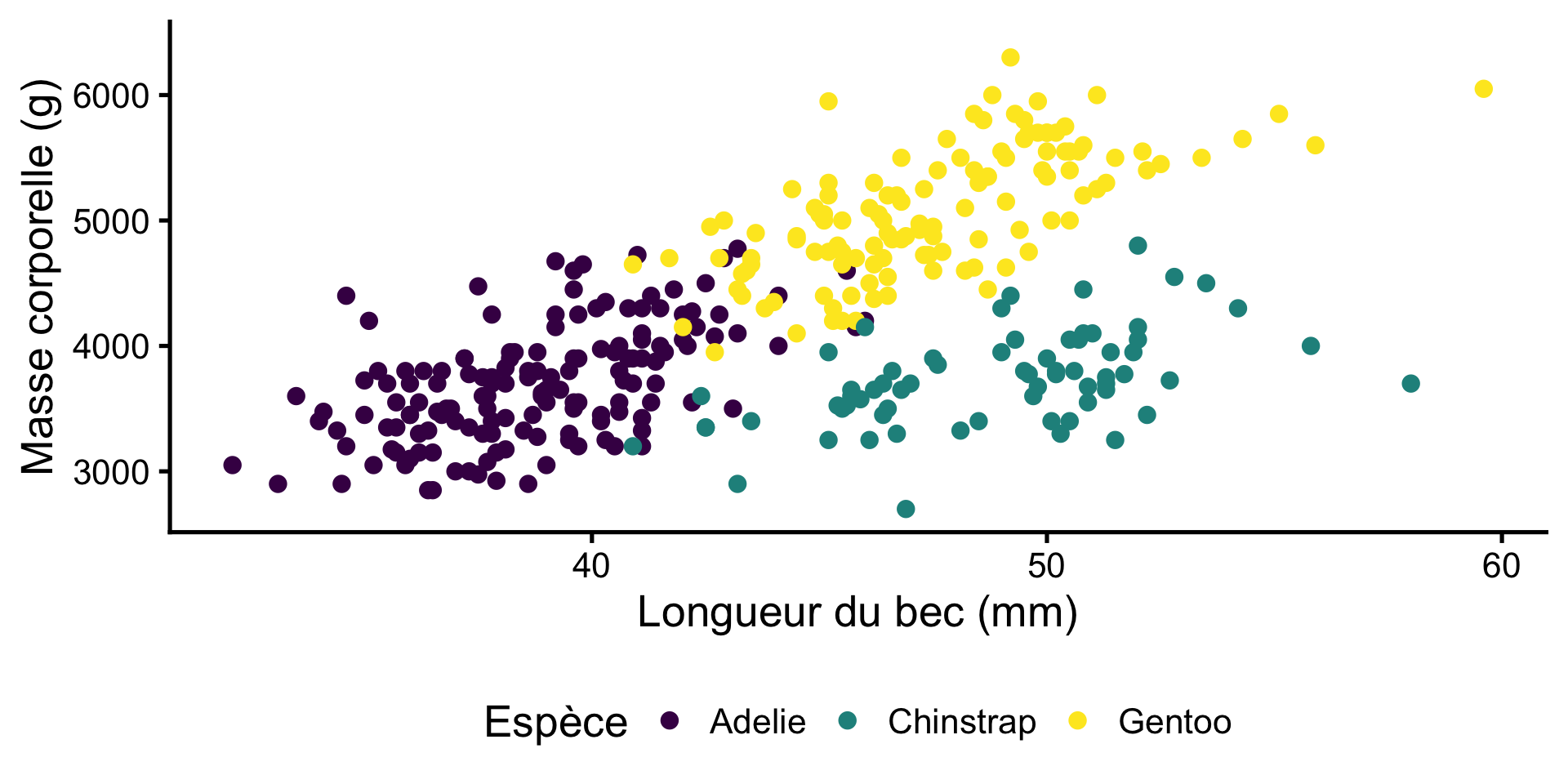
Poids et Longueur
Comment pouvons-nous utiliser un modèle statistique pour ces données?
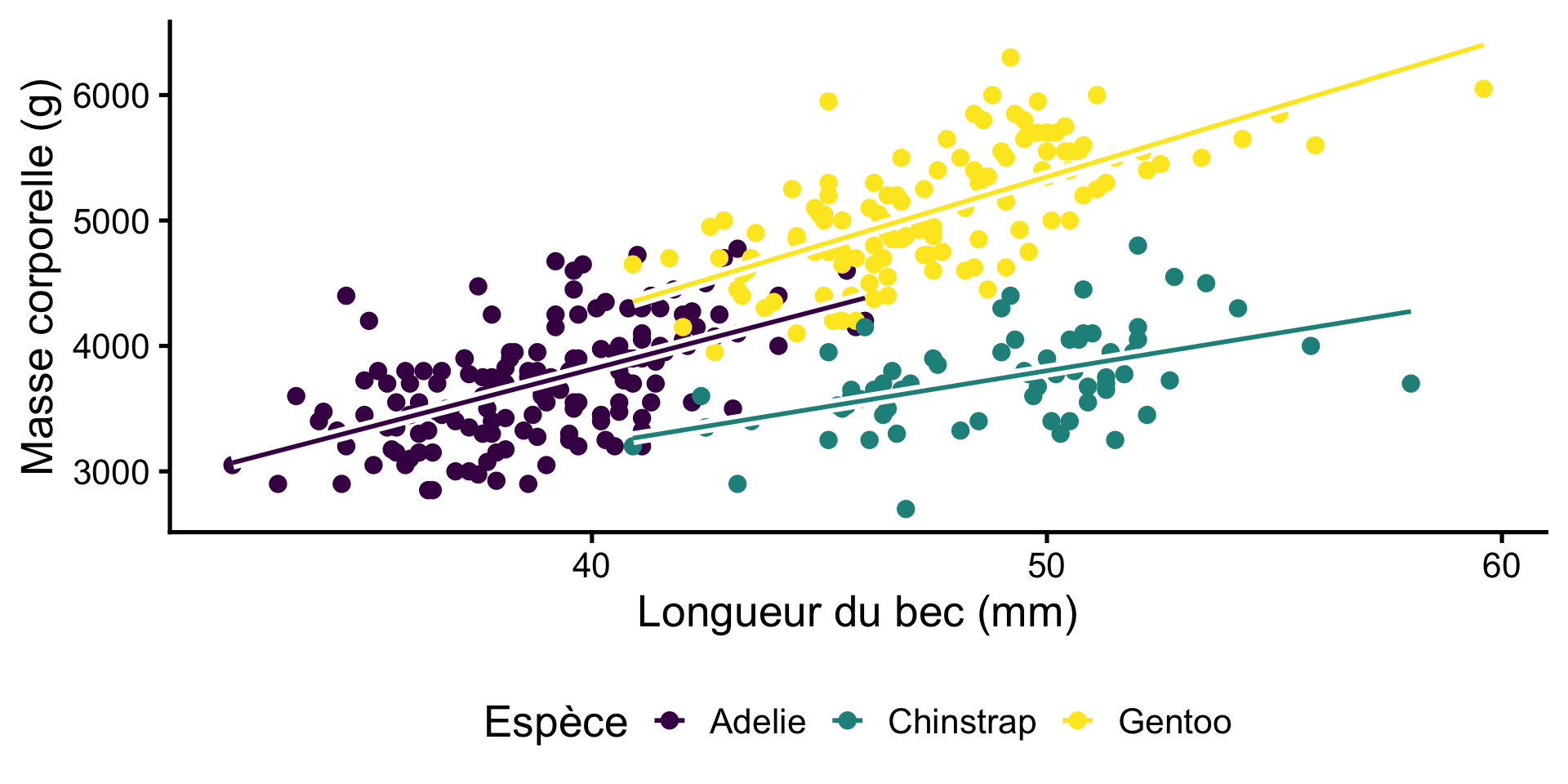
Poids et Longueur
Comment pouvons-nous utiliser un modèle statistique pour ces données?
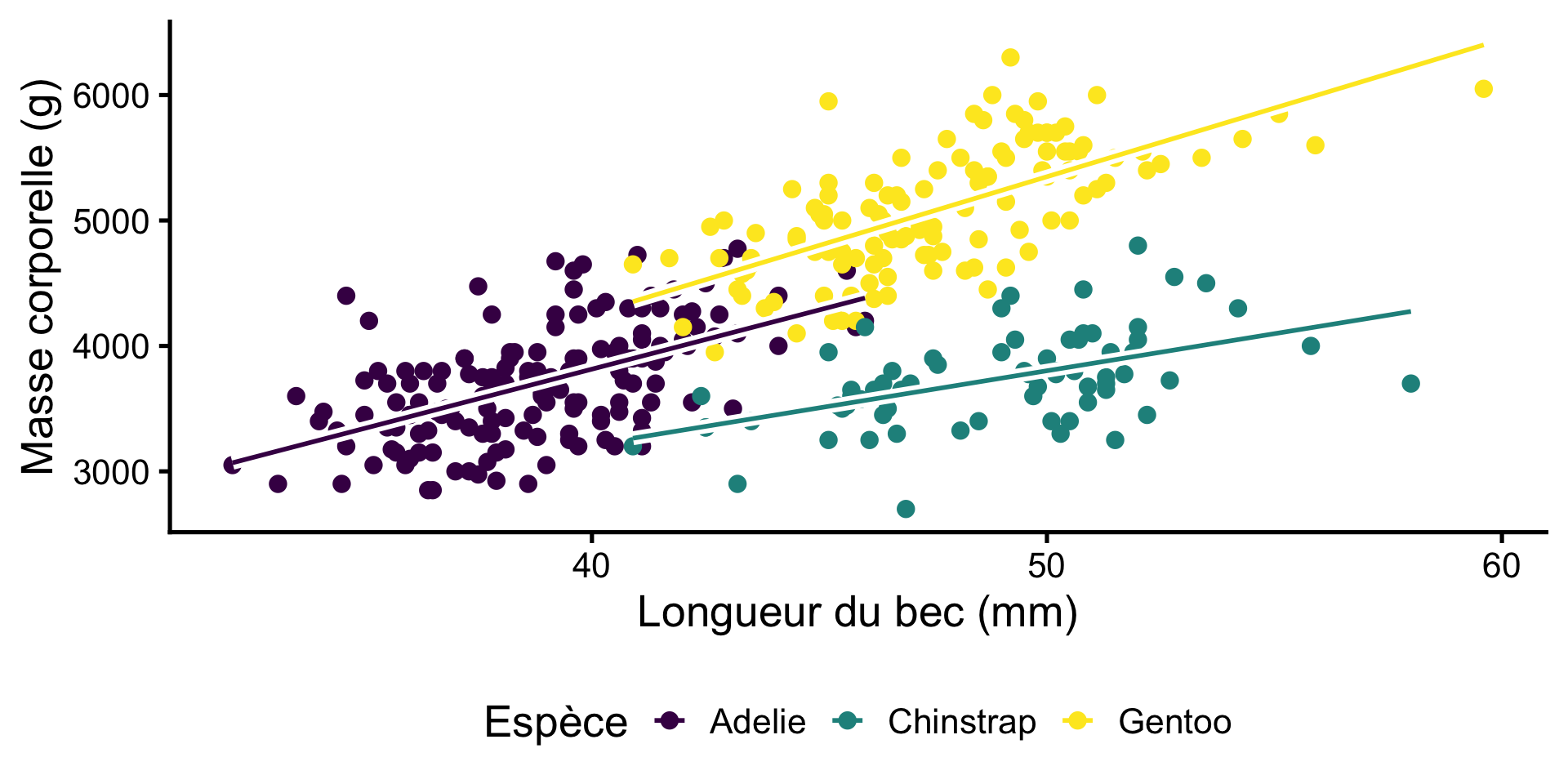
Un tel modèle pourrait être utile pour
Tester si cette relation est statistiquement significative
Estimer le poids en fonction de la taille
Poids et Longueur
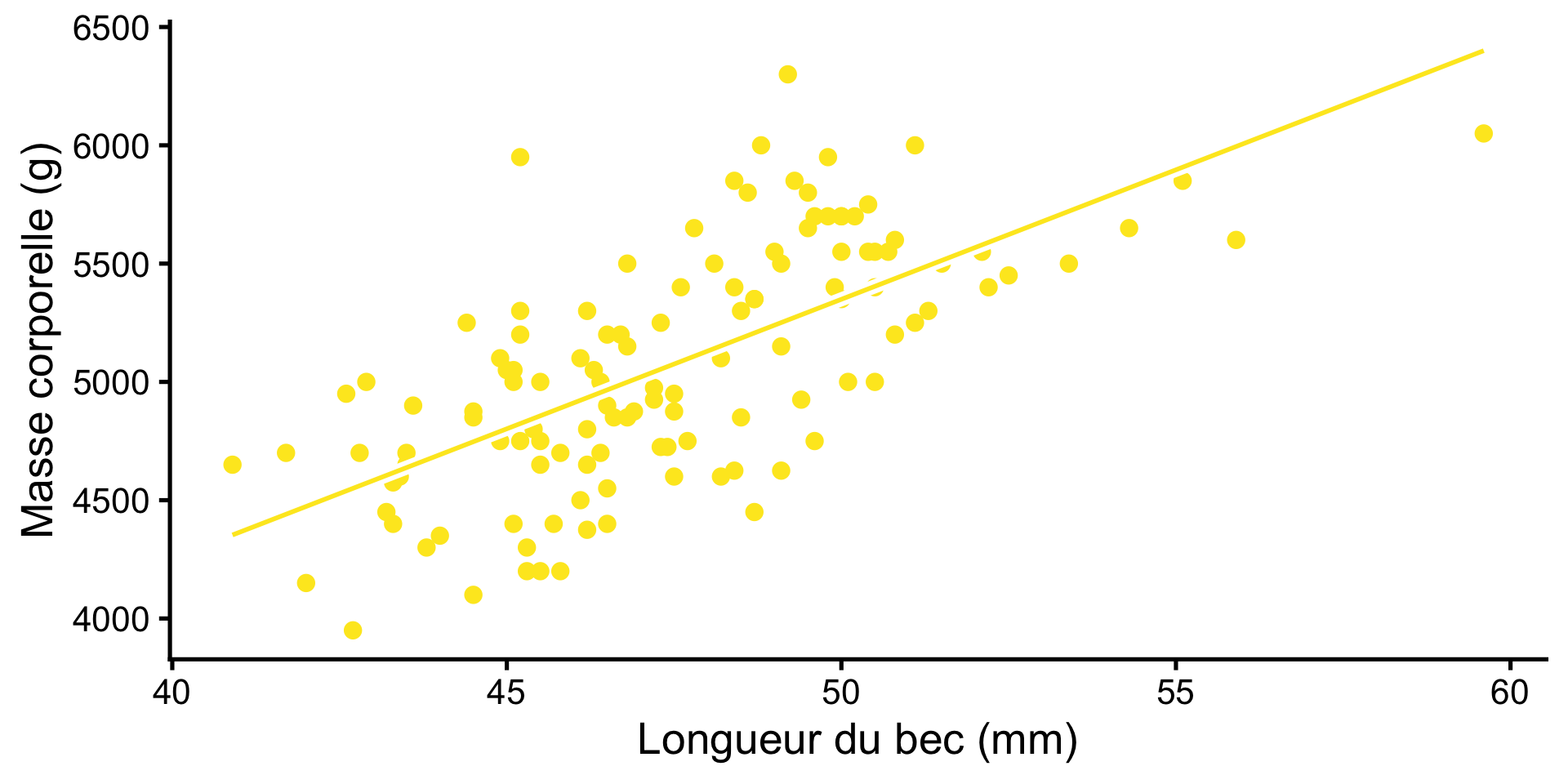
Mais pas à pas !
Modèle de relation pour les manchots Gentoo
- Response variable: Masse corporelle
- Explanatory variable: Longueur du bec
Avant
\[ \mathrm{Weight}_i \sim \mathrm{Normal(\mu}_i,~\mathrm{\sigma)} \\ \]
Après
\[ \begin{align} \mathrm{Weight}_i \sim \mathrm{Normal(\mu}_i,~\mathrm{\sigma)} \\ \mu_i = a + b \cdot \mathrm{billlength}_i \end{align} \]
\(a\) est l’ordonnée à l’origine
\(b\) est la pente
Poids et Longueur
Connaissez-vous un autre nom pour ce type de modèle ?
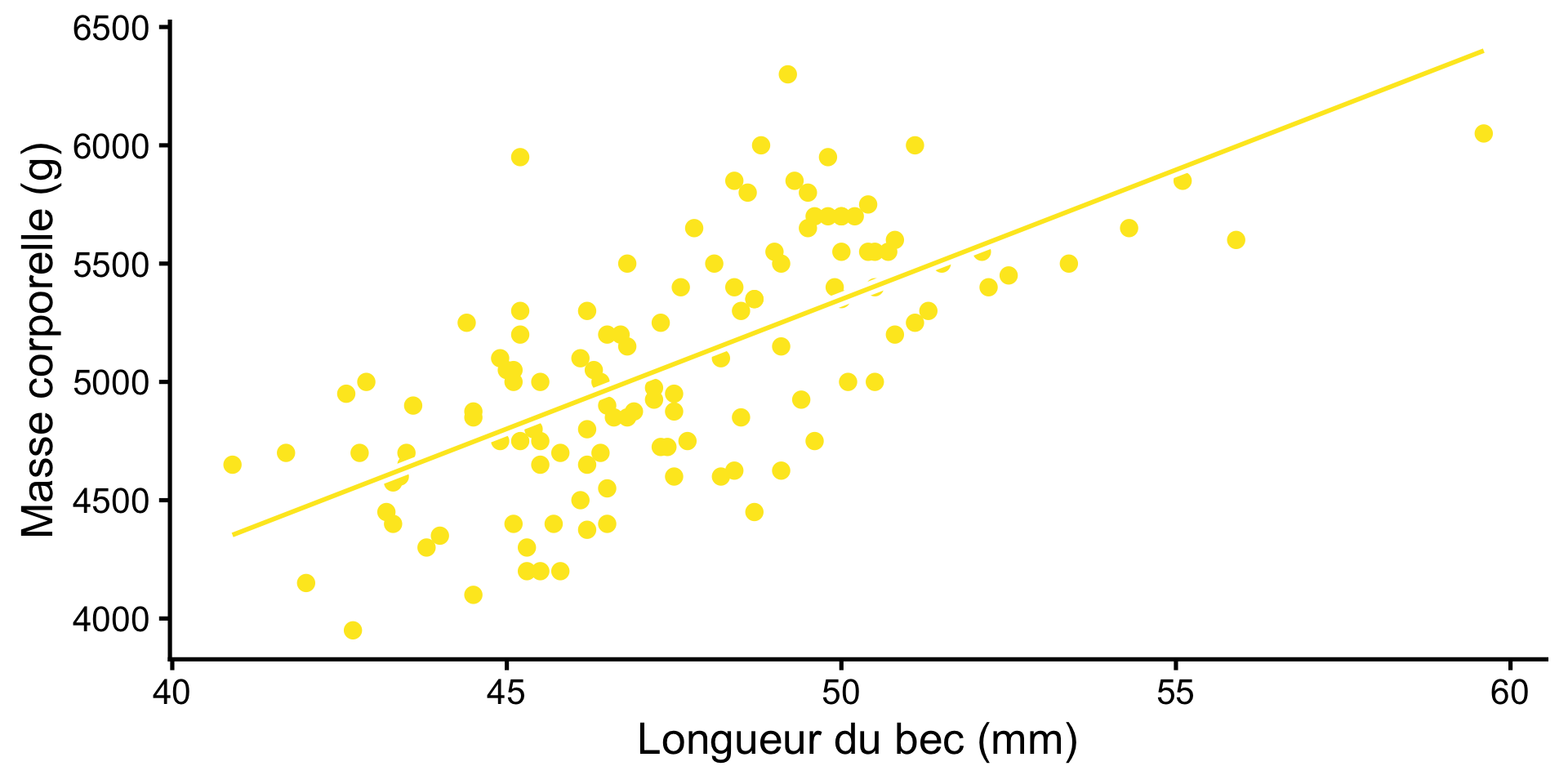
\[ \begin{align} \mathrm{Weight}_i \sim \mathrm{Normal(\mu}_i,~\mathrm{\sigma)} \\ \mu_i = a + b \cdot \mathrm{billlength}_i\\ \mu_i = -123.8 + 109.5 \cdot \mathrm{billlength}_i \end{align} \]
Un modèle linéaire, avec une variable explicative numérique, est équivalent à une régression !
Différence de poids
Une relation positive entre le poids et la longueur du bec n’est pas biologiquement surprenante
Mieux : Tester les différences de poids entre les espèces de manchots
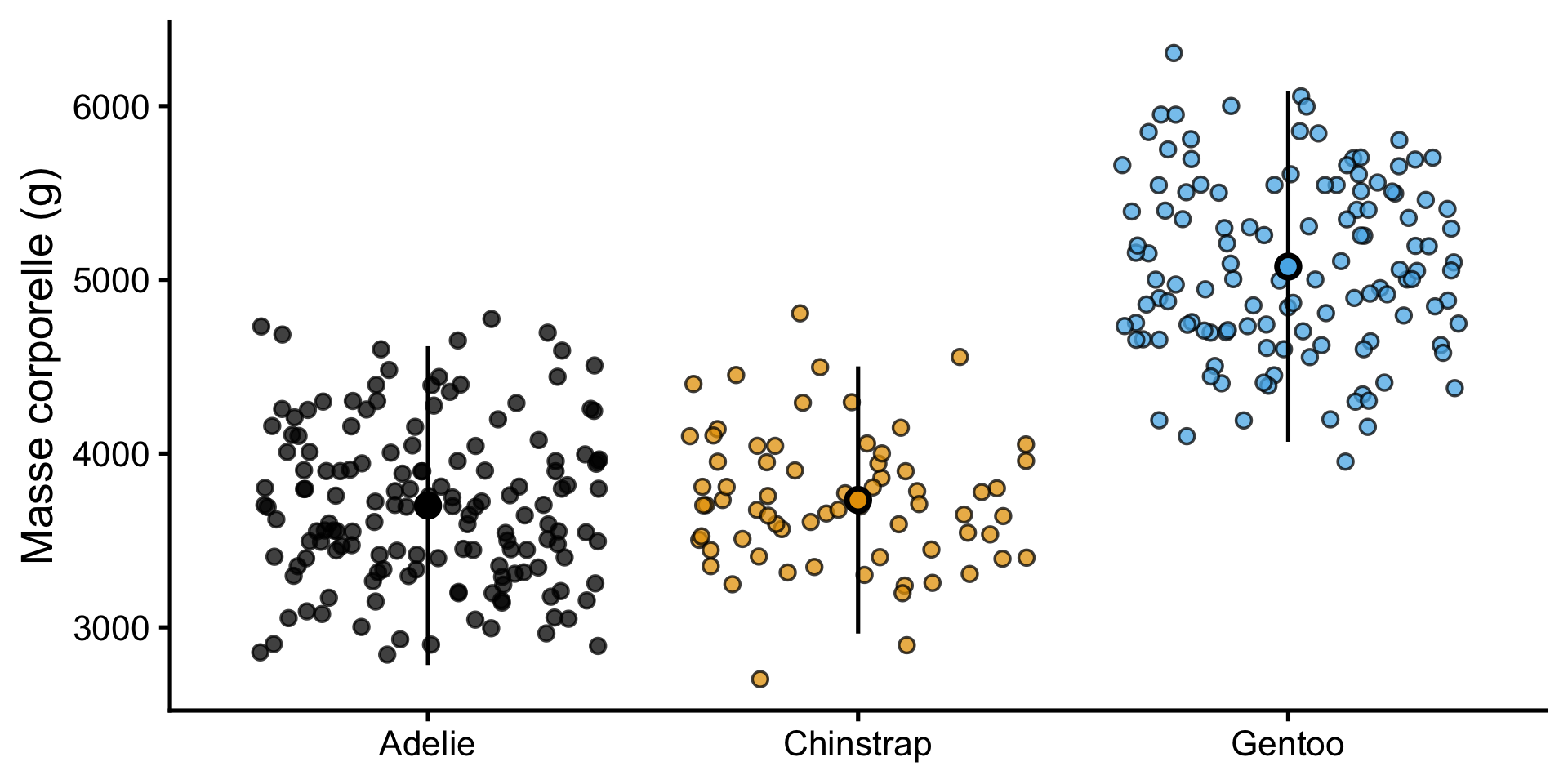
Model
\[ \begin{align} \mathrm{Weight}_i \sim \mathrm{Normal(\mu}_i,~\mathrm{\sigma)} \\ \mu_i = \mu_{\text{species}[i]} \end{align} \]
, où \({\mathrm{species}[i]}\) est l’espèce du manchot \(i\) et \(\mu_\text{species}\) est le poids moyen de cette espèce.
Différence de poids
Modèle en R:
# fmt: skip
m_spec <- lm(body_mass_g ~ species,
data = penguins)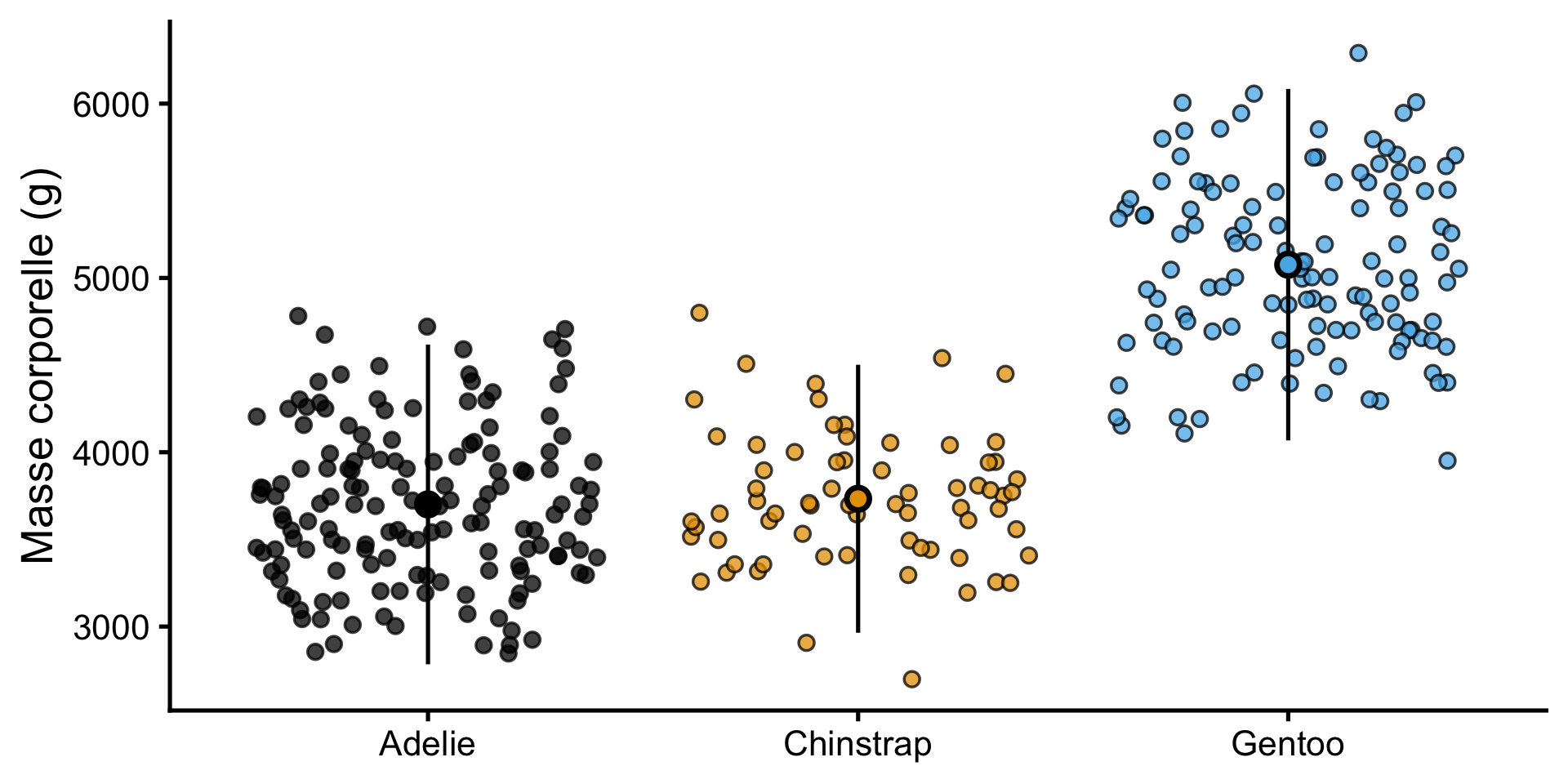
Voir les coefficients :
summary(m_spec)
Call:
lm(formula = body_mass_g ~ species, data = penguins)
Residuals:
Min 1Q Median 3Q Max
-1126.02 -333.09 -33.09 316.91 1223.98
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3700.66 37.62 98.37 <2e-16 ***
speciesChinstrap 32.43 67.51 0.48 0.631
speciesGentoo 1375.35 56.15 24.50 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 462.3 on 339 degrees of freedom
(2 observations deleted due to missingness)
Multiple R-squared: 0.6697, Adjusted R-squared: 0.6677
F-statistic: 343.6 on 2 and 339 DF, p-value: < 2.2e-16| Espèce | Moyenne réelle | Calcul avec coefficients |
|---|---|---|
| Adelie | 3701 | 3700.66 |
| Chinstrap | 3733 | 3700.66 + 32.43 = 3733.09 |
| Gentoo | 5076 | 3700.66 + 1375.35 = 5076.01 |