Distributions statistiques alternatives
Cours 6
Normalité des résidus
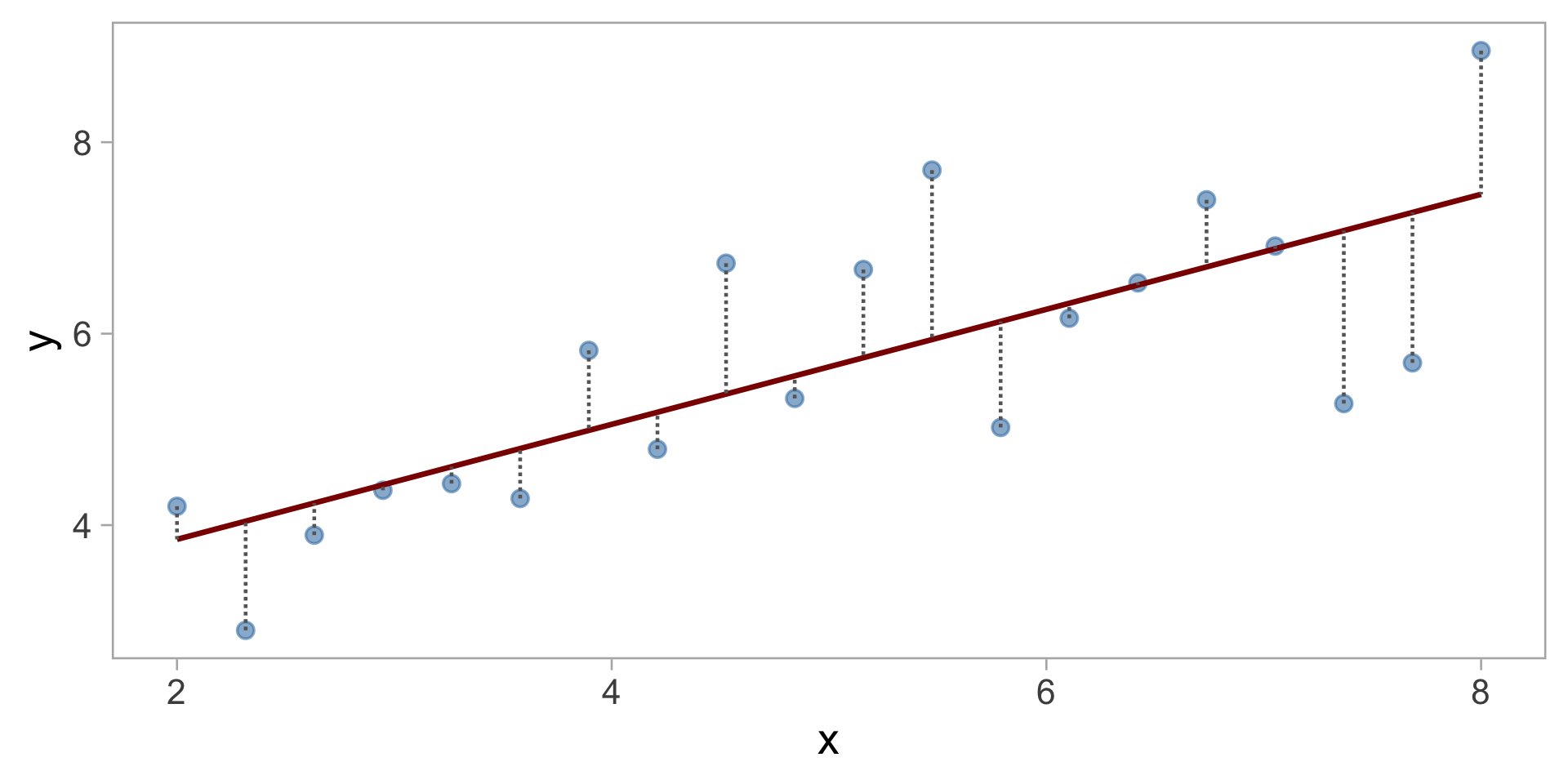
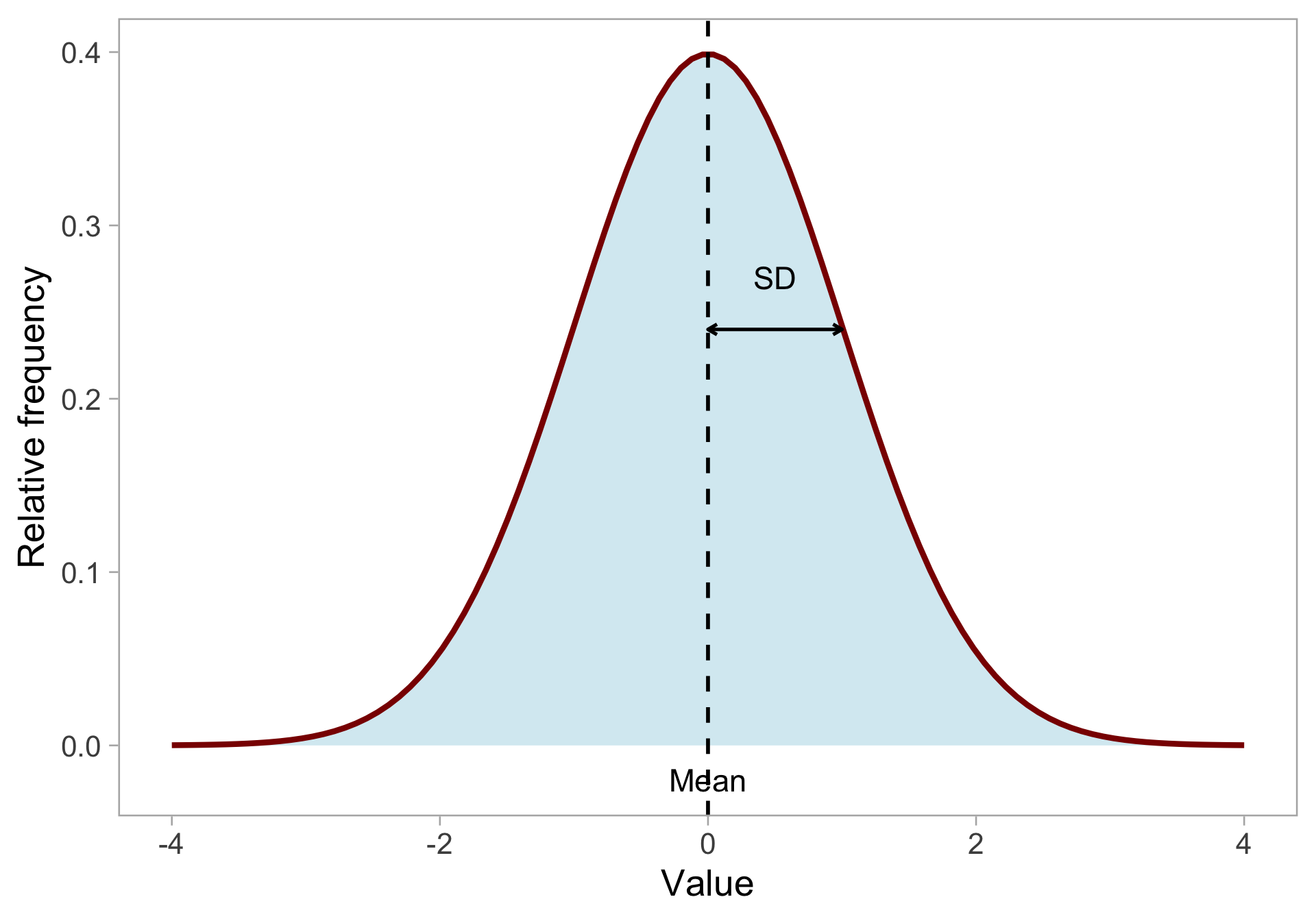
Les résidus (différence entre les données et les prédictions) suivent la normalité
Pas les données brutes elles-mêmes
\(\mathrm{residual}_i = y_i - \mu_i\)
La distribution normale décrit le bruit aléatoire autour de la droite de régression
\[ \begin{align} y_i &\sim \mathrm{Normal}(\mu_i, \sigma) \\ \mu_i &= a + b \cdot x_i \end{align} \]
Exemple 1 : Comptage d’oursins
Vous comptez le nombre d’oursins dans des quadrats de 1 m²
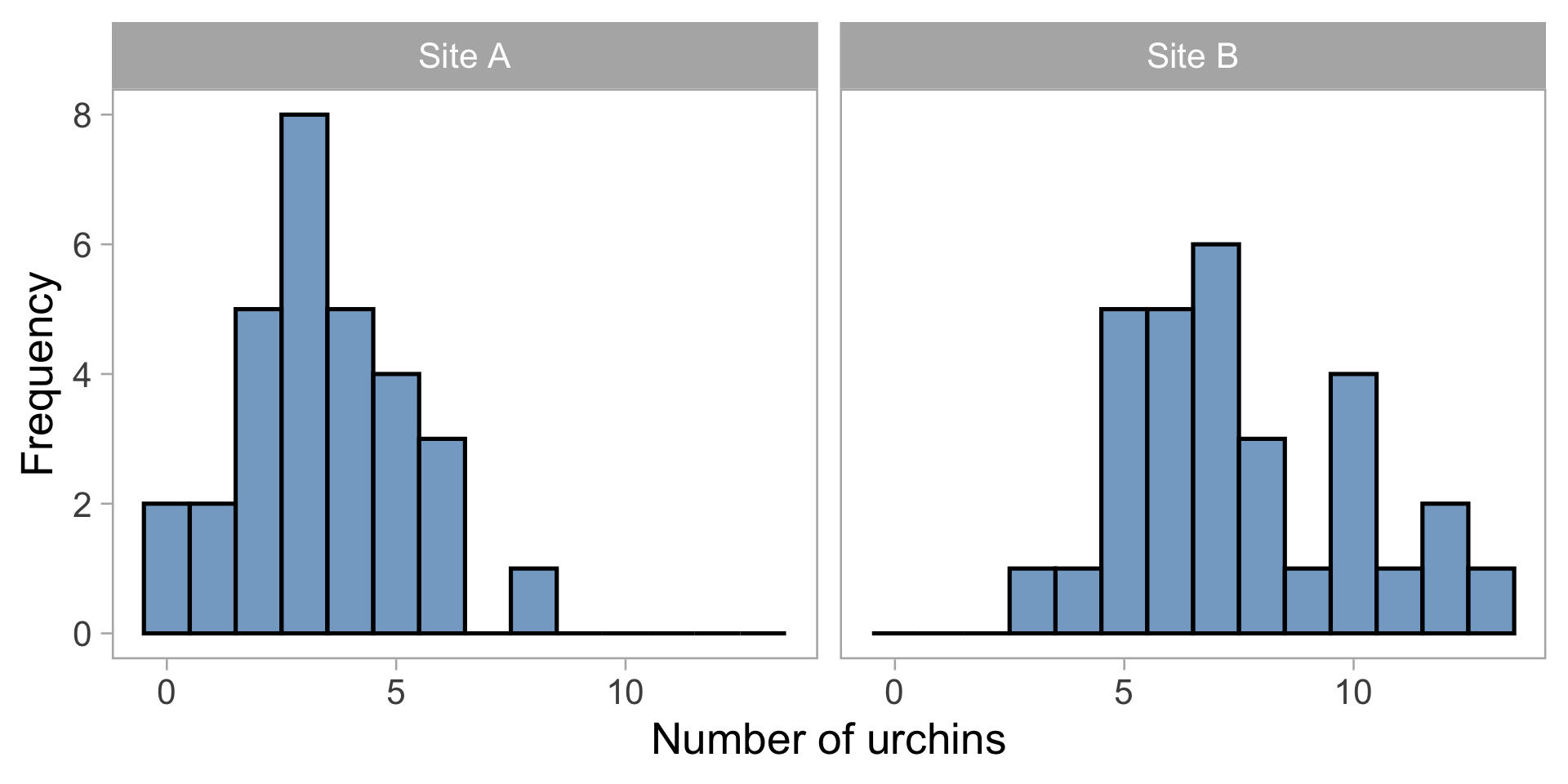
Problèmes avec un modèle normal :
- Les comptages sont des entiers (0, 1, 2, …)
- Aucune valeur négative possible
- La variance augmente souvent avec la moyenne
- Distribution asymétrique
Exemple 2 : Transects linéaires
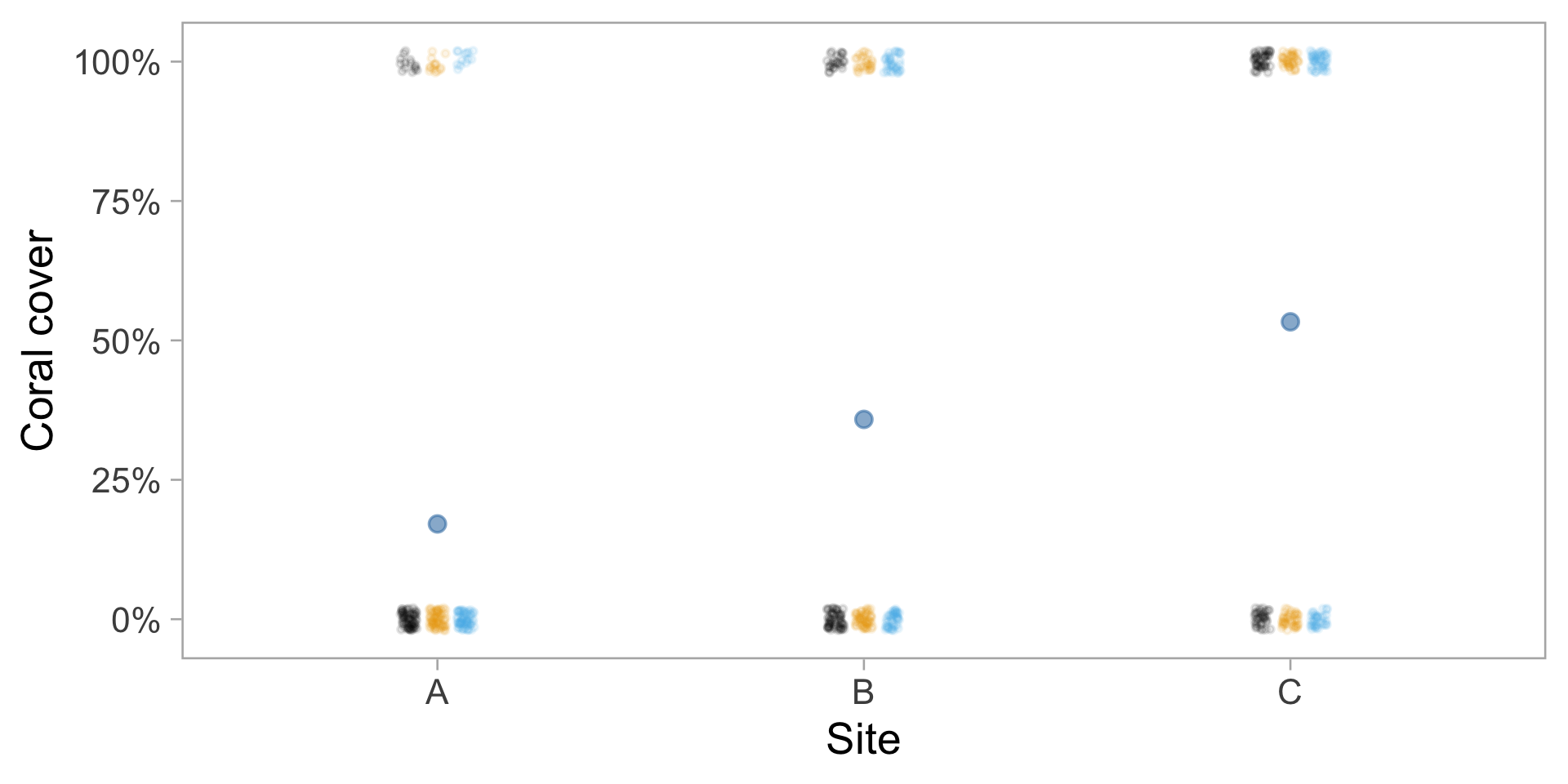
Couverture corallienne
- 3 transects de 20 m par site
- Intervalles de 25 cm (80 points par transect)
- Enregistrer si le corail est présent ou absent
Problèmes avec un modèle normal :
- La réponse est une proportion (0 à 1)
- Le modèle pourrait prédire des valeurs < 0 ou > 1
- Les résidus ne peuvent pas être normaux
- La variance dépend de la proportion (plus élevée près de 0.5)
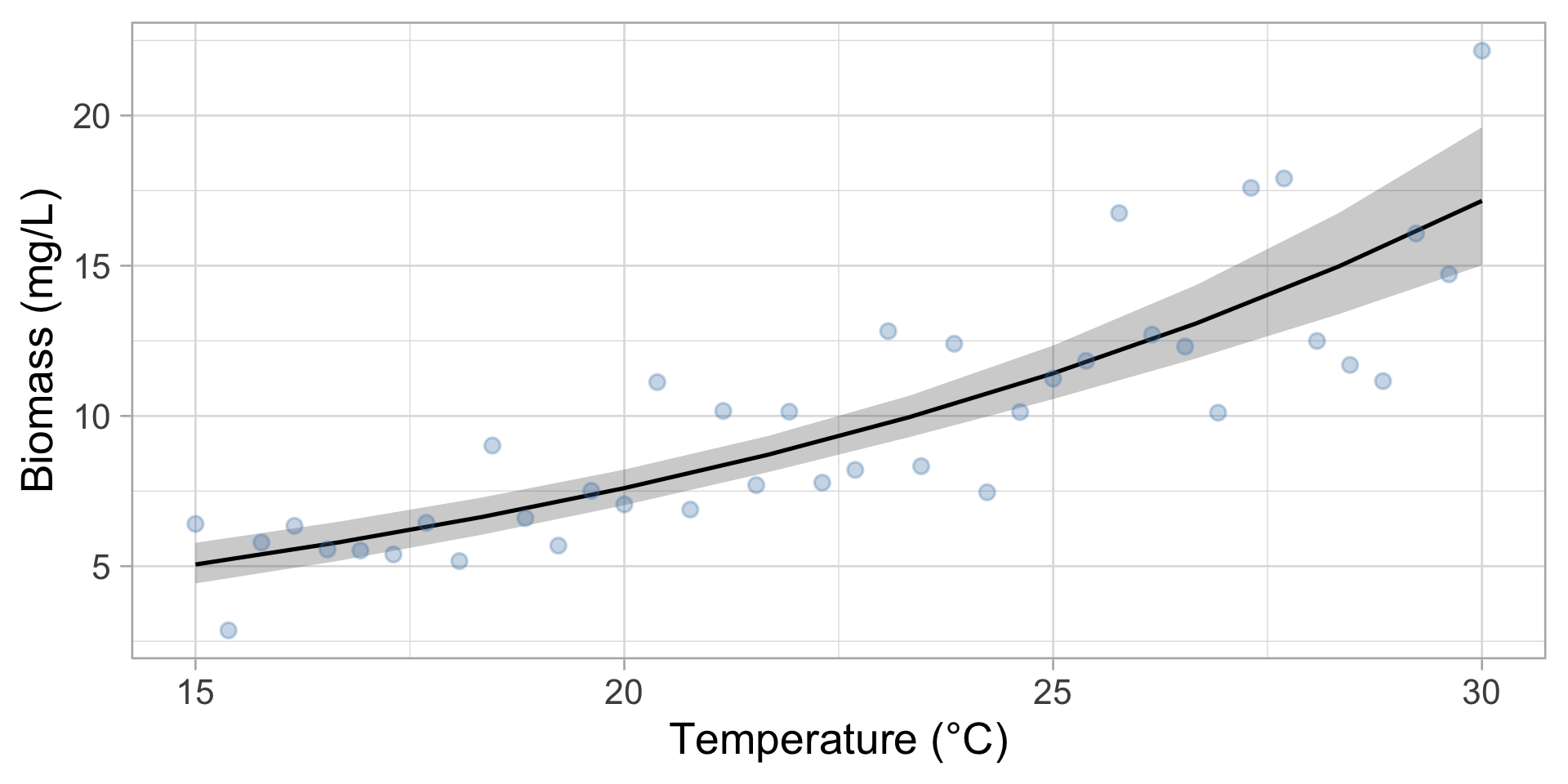
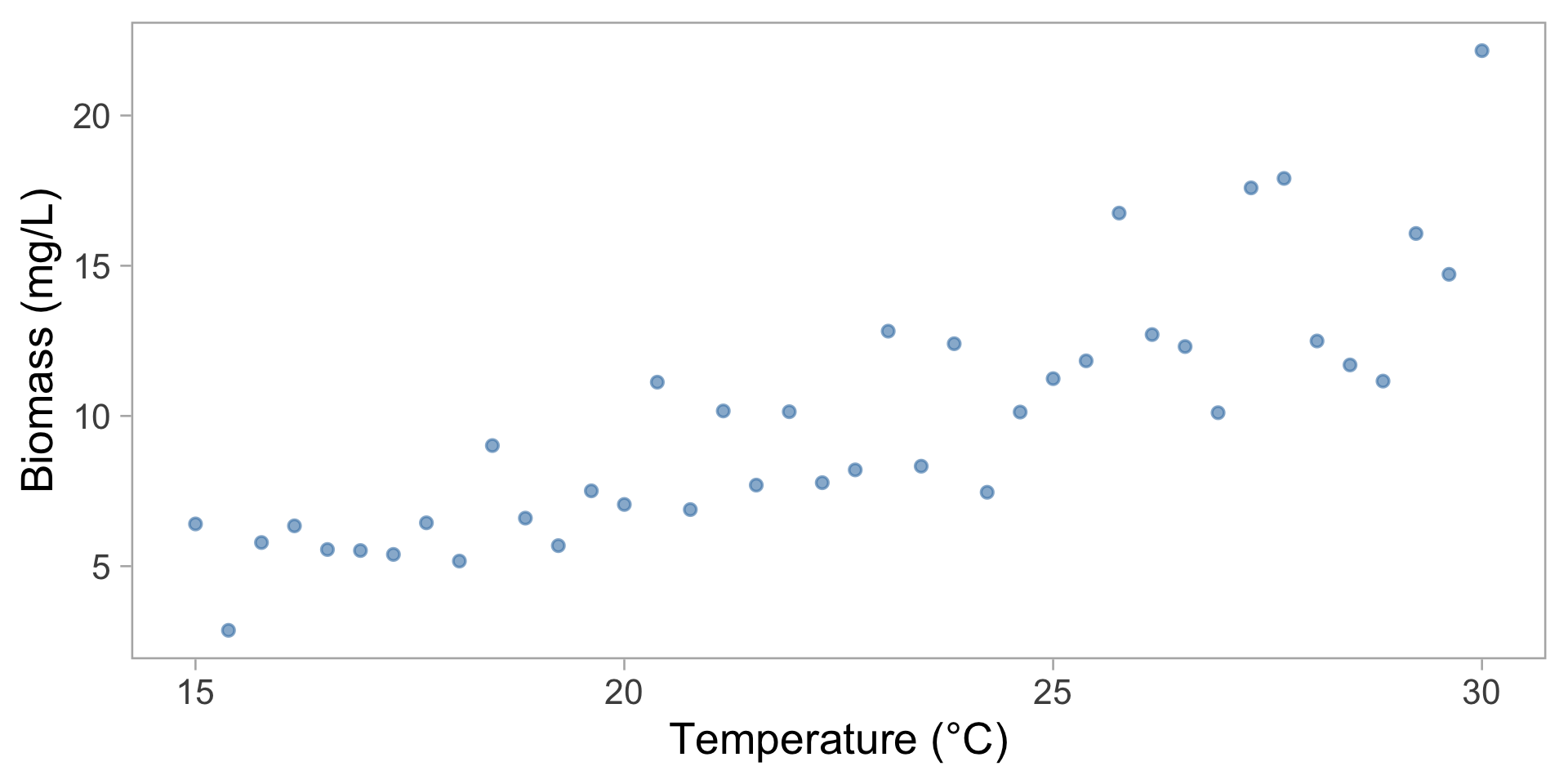
Exemple 3 : Biomasse de phytoplancton
Vous mesurez la biomasse (mg/L) en fonction de la température
Problèmes avec un modèle normal :
- La biomasse ne peut pas être négative
- La variance augmente avec la moyenne
- Distribution asymétrique (longue queue vers la droite)
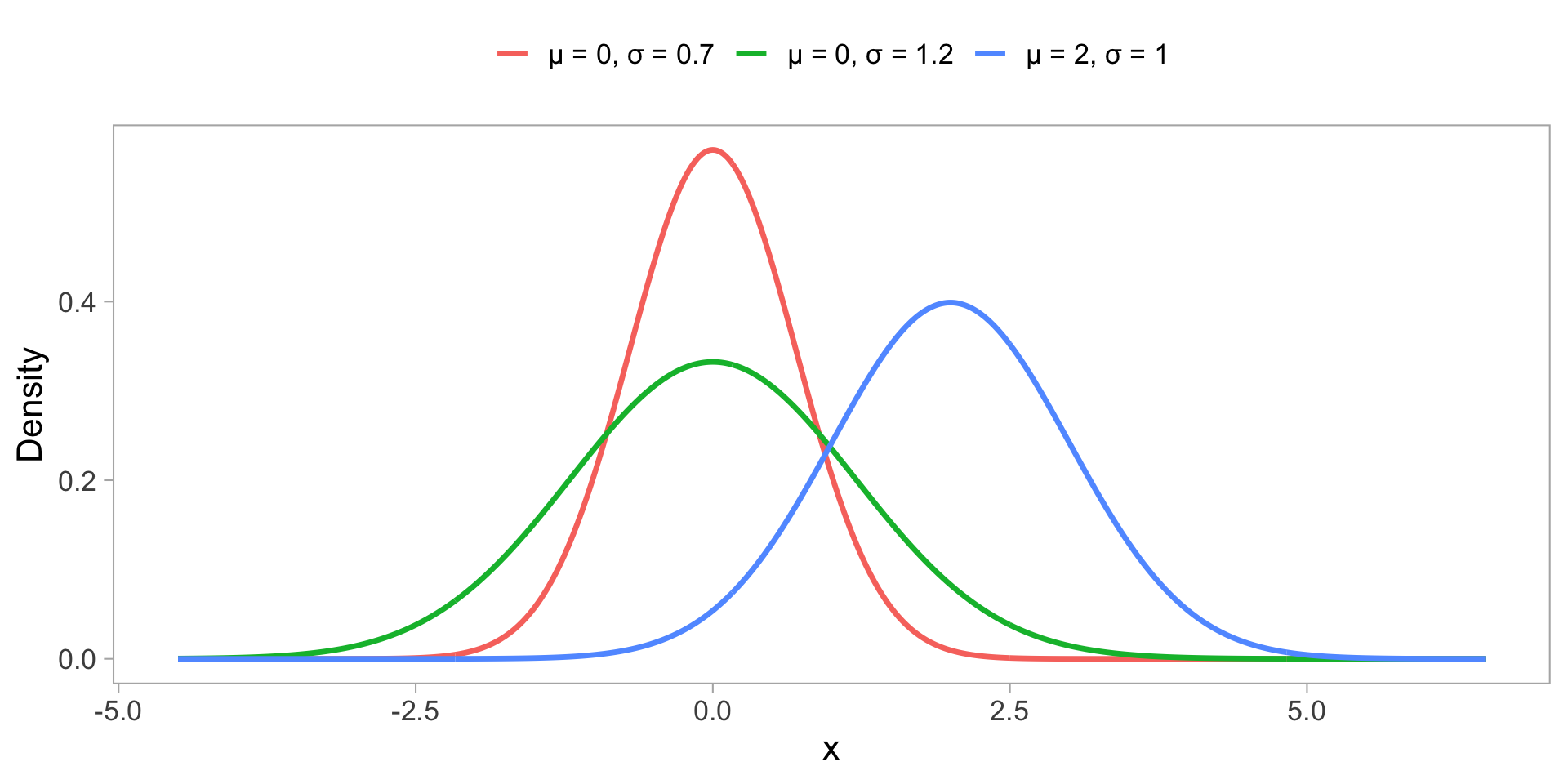
Forme des distributions - Normal
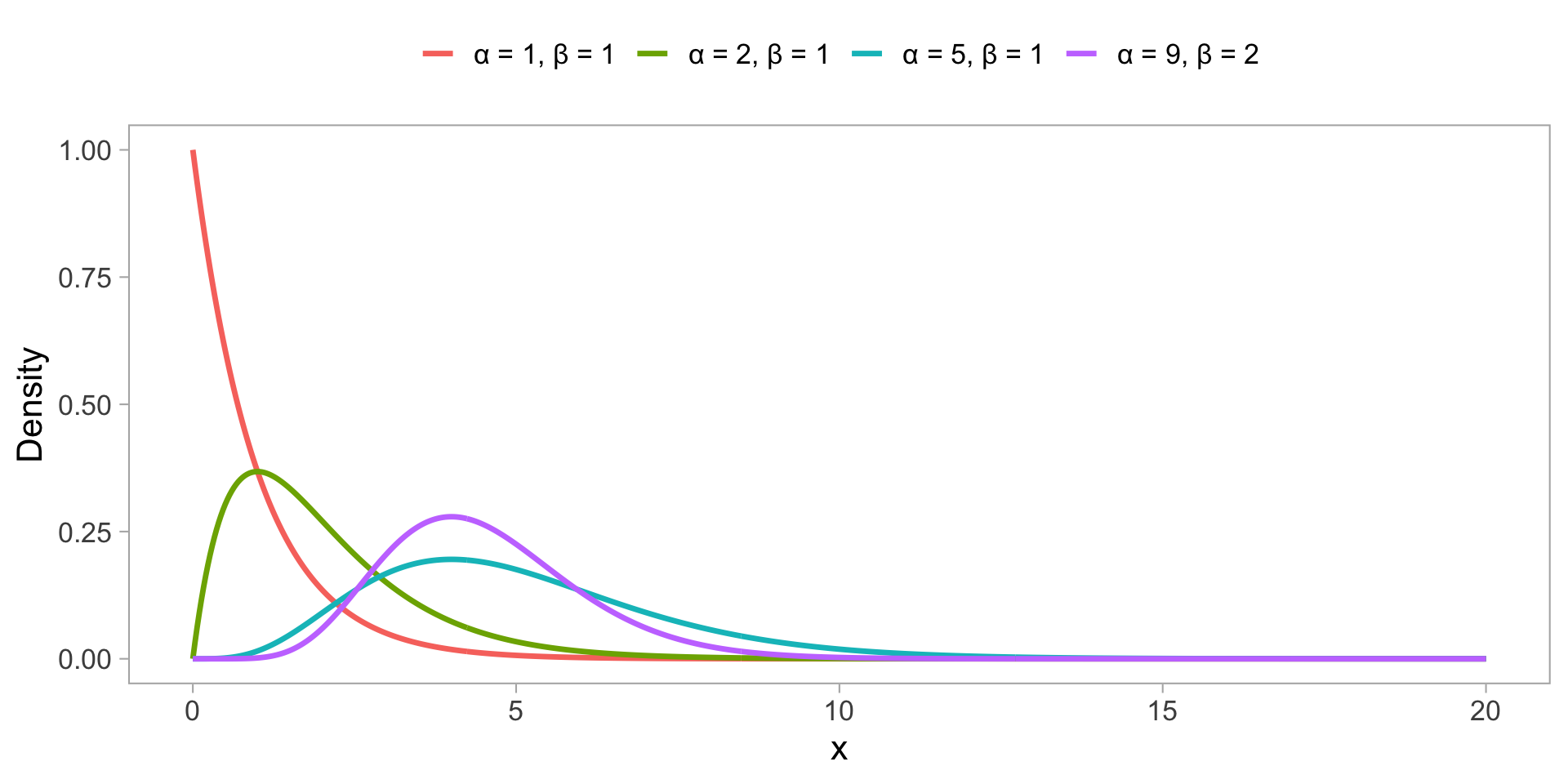
Forme des distributions - Gamma
Forme des distributions - Poisson
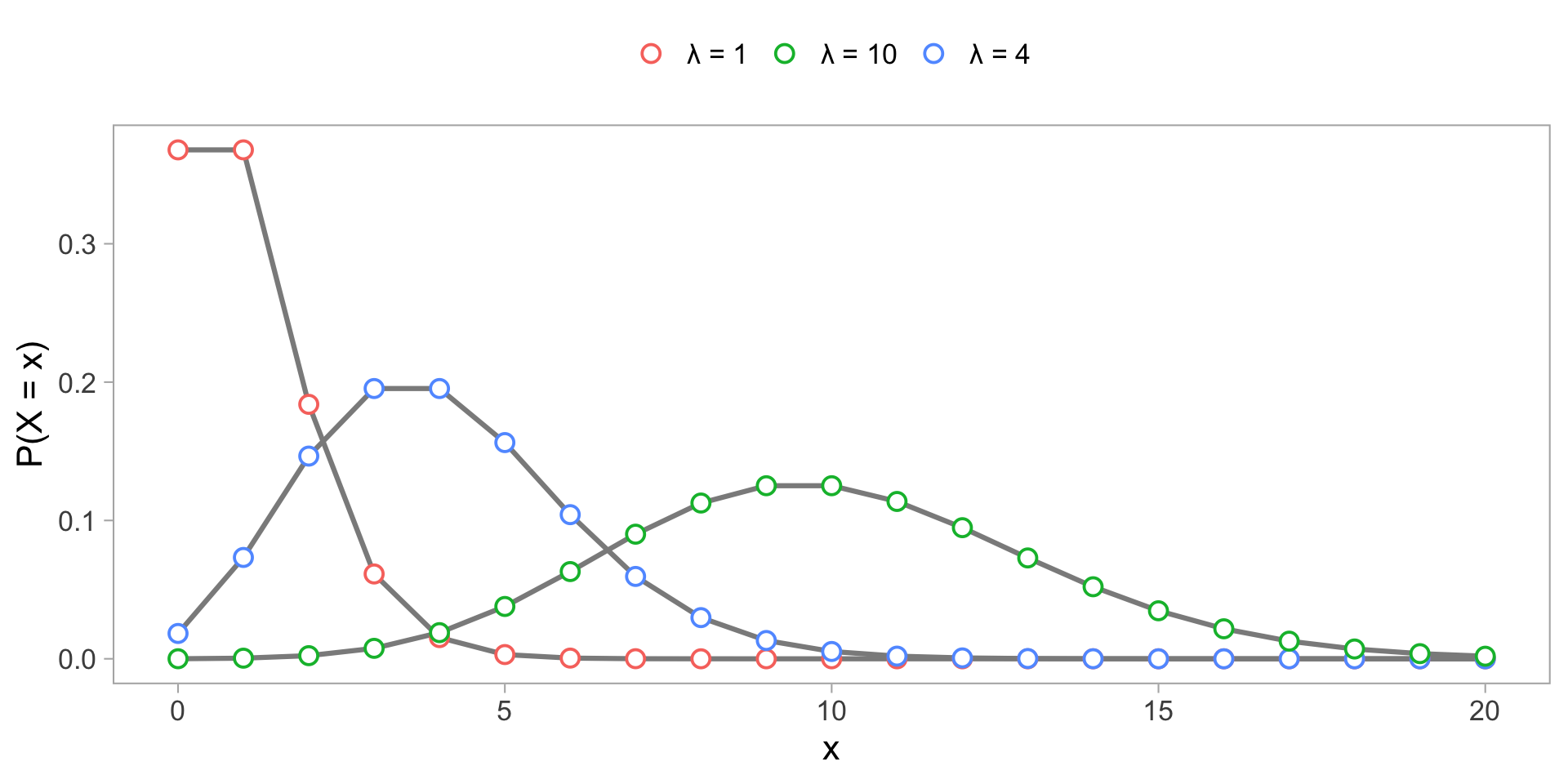
GLM Poisson : Comptage d’oursins
GLM Poisson : Comptage d’oursins
Visualisation
#fmt: skip
estimate_means(m_poisson) %>%
plot()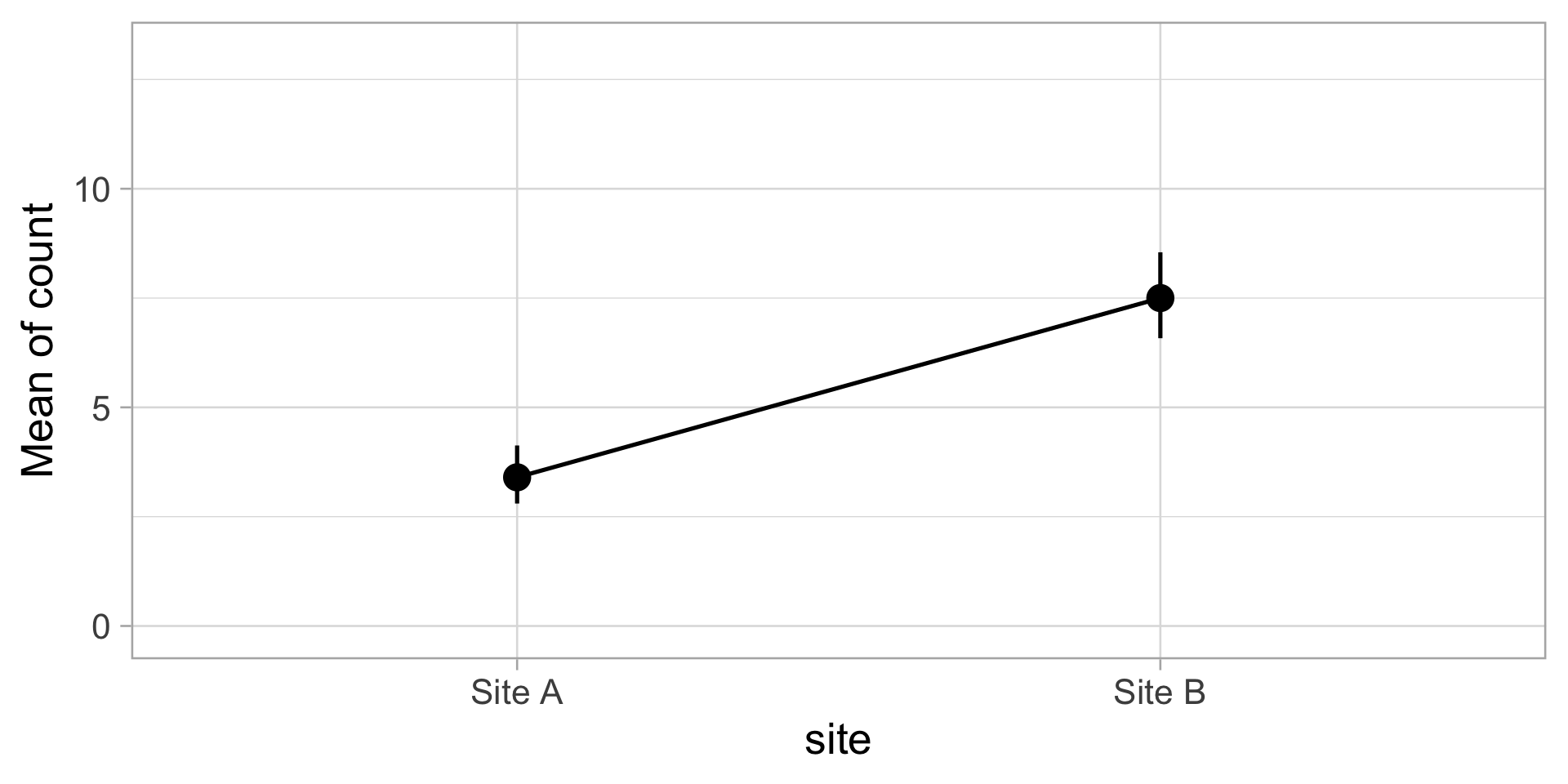
GLM Poisson : Comptage d’oursins
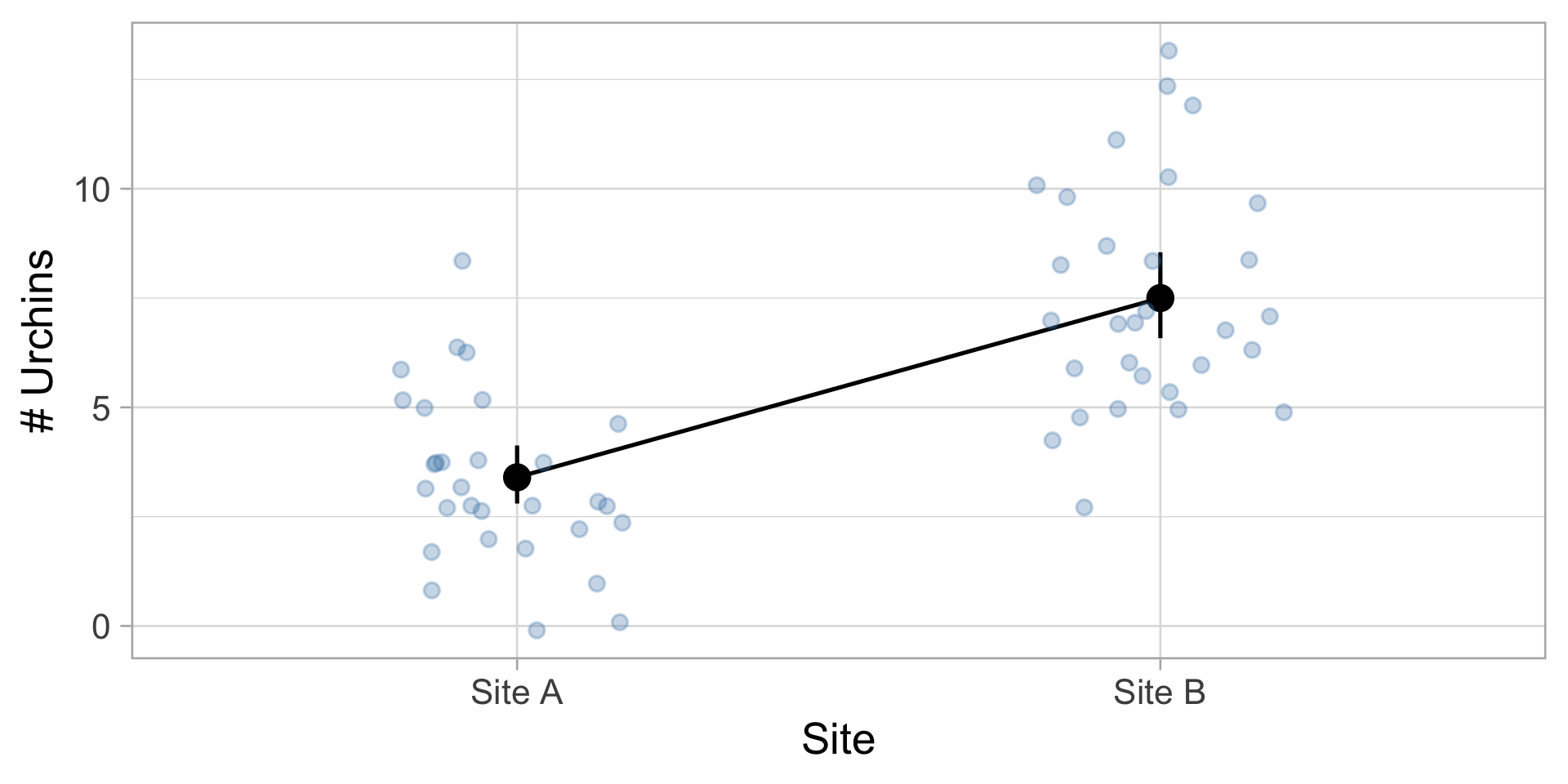
Visualisation
#fmt: skip
estimate_means(m_poisson) %>%
plot() +
labs(x = "Site",
y = "# Urchins") +
geom_jitter(
data = count_data,
aes(x = site, y = count),
width = .2,
col = "steelblue",
alpha = .3
)
GLM Binomiale : Couverture corallienne
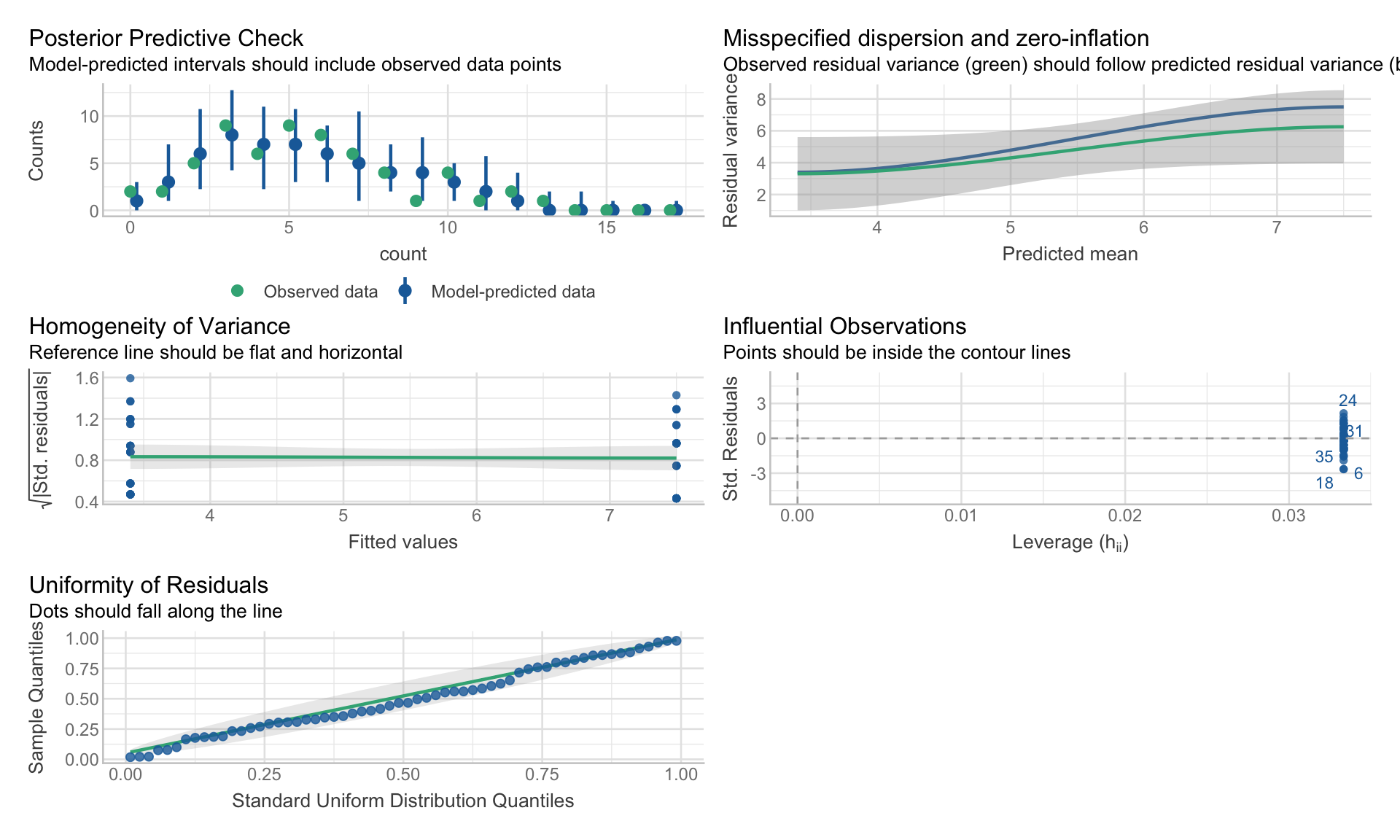
Vérifier les hypothèses
check_model(m_coral)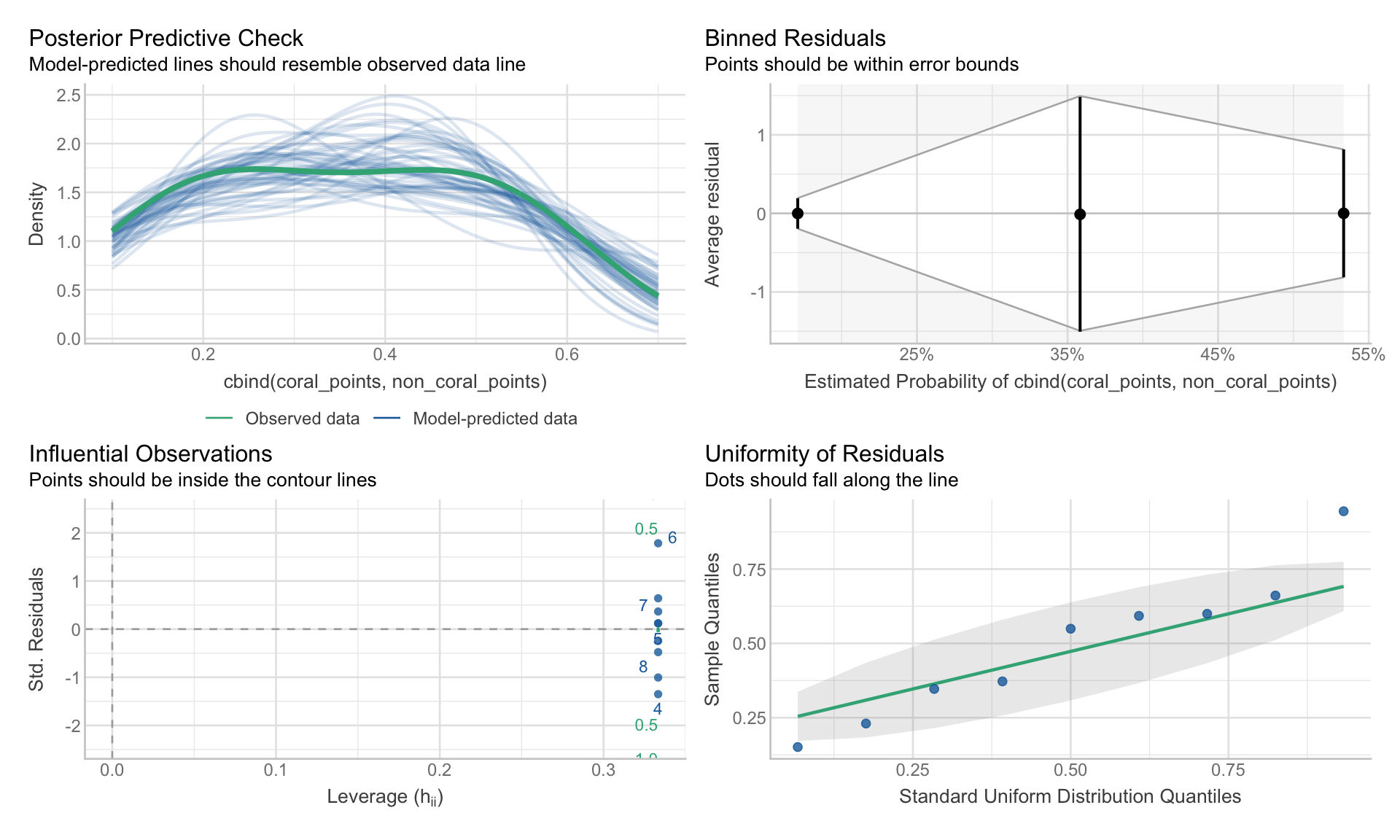
GLM Binomiale : Couverture corallienne
Visualisation
#fmt: skip
estimate_means(m_coral) %>%
plot()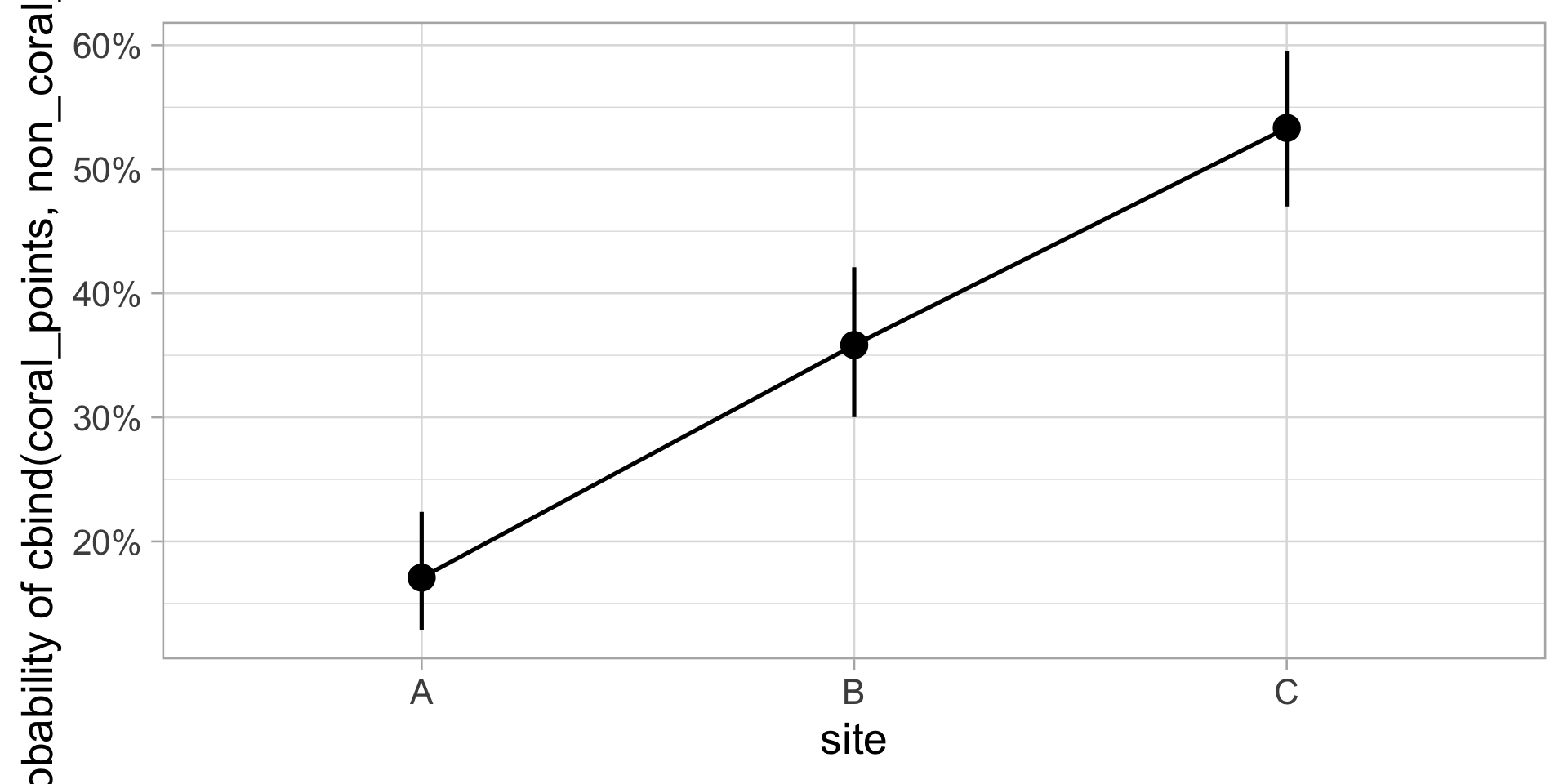
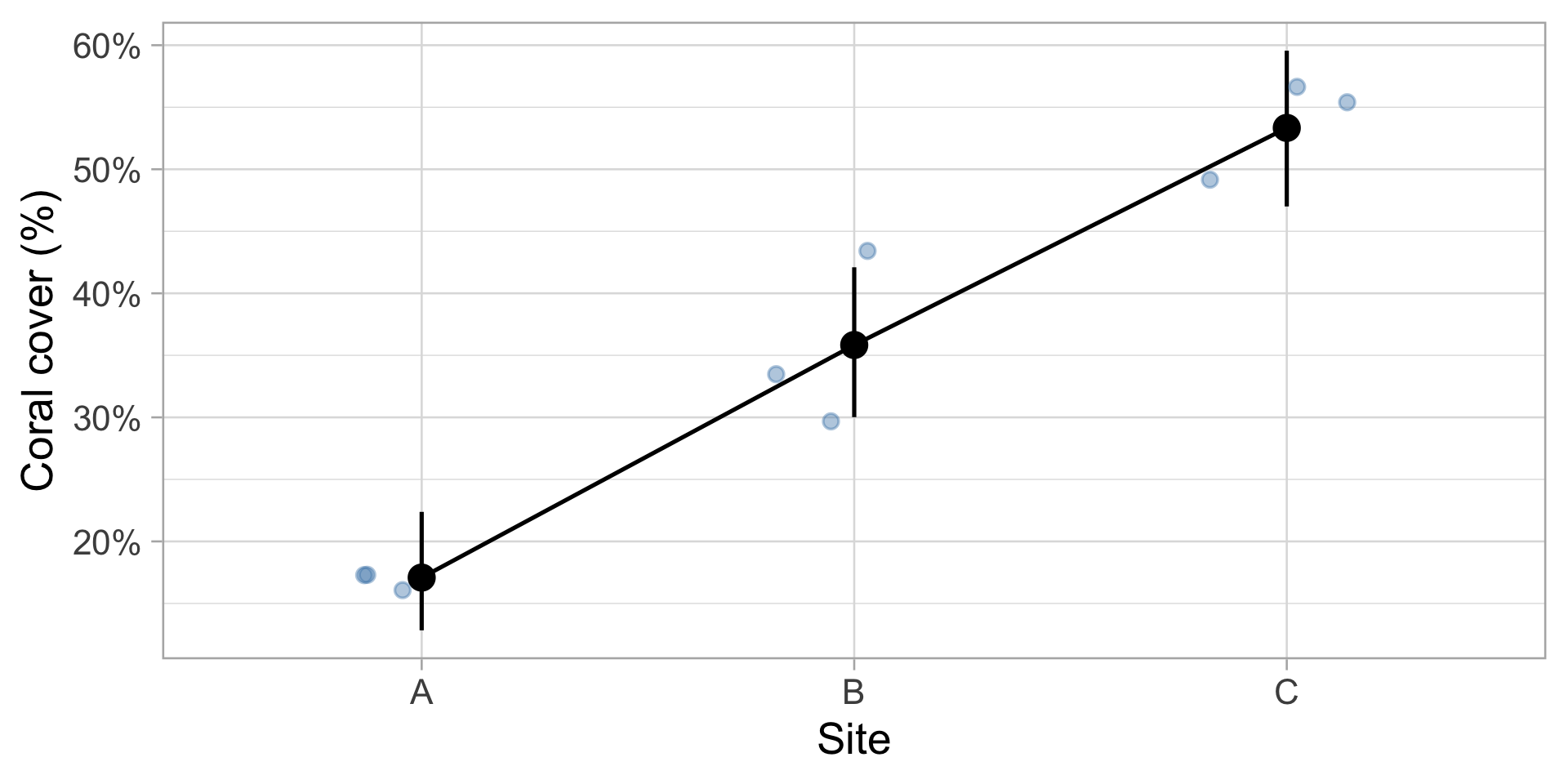
GLM Binomiale : Couverture corallienne
Visualisation
#fmt: skip
estimate_means(m_coral) %>%
plot() +
labs(x = "Site",
y = "Coral cover (%)") +
geom_jitter(
data = df_coral_pa,
aes(x = site,
y = coral_points / n_points),
col = "steelblue",
alpha = .4
)
GLM Gamma : Biomasse de plancton
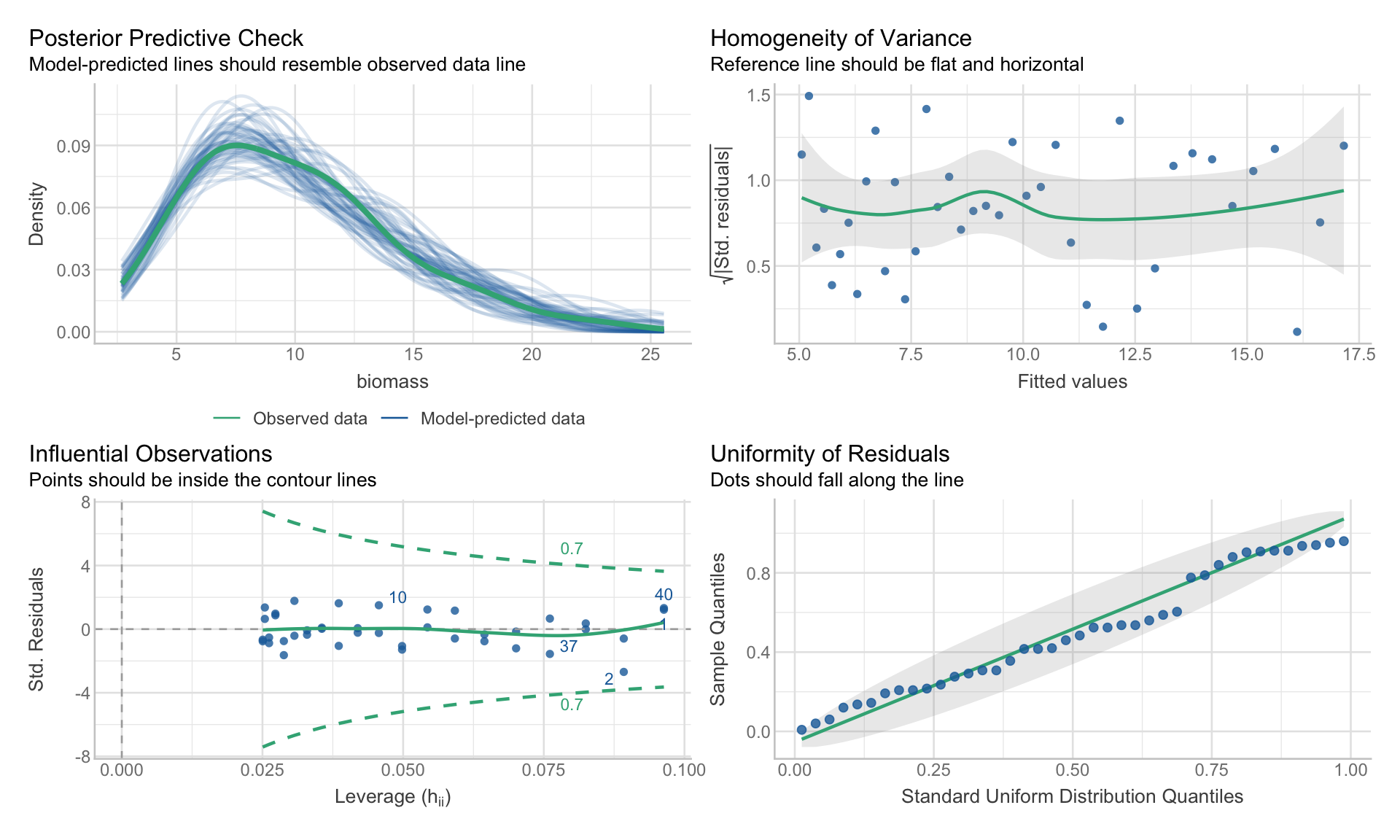
GLM Gamma : Biomasse de plancton
Visualisation
#fmt: skip
estimate_relation(m_gamma) %>%
plot()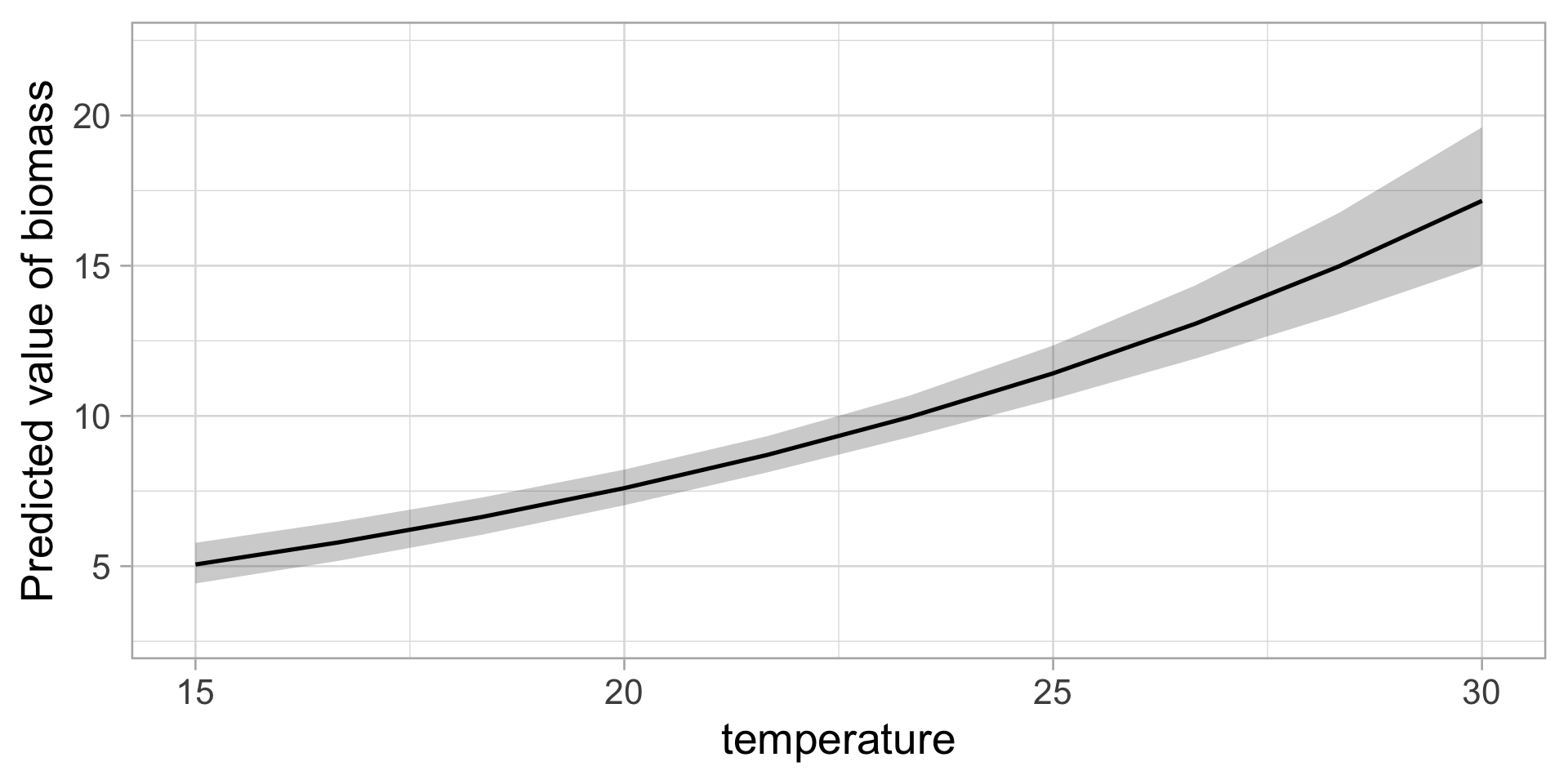
GLM Gamma : Biomasse de plancton
Visualisation
#fmt: skip
estimate_relation(m_gamma) %>%
plot() +
labs(x = "Temperature (°C)",
y = "Biomass (mg/L)") +
geom_point(
data = df_biomass,
aes(x = temperature,
y = biomass),
col = "steelblue",
alpha = .3
)